
- 딥러닝
- deep learning
- object detection
- overfeat
- LeNet 구현
- Optimizer
- Weight initialization
- Convolution 종류
- image classification
- SPP-Net
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Today
- Total
I'm Lim
[논문 정리] ResNet-D 본문
Paper
He, Tong, et al. "Bag of tricks for image classification with convolutional neural networks." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
Abstract
본 논문은 ResNet 모델의 Ablation study로써, ResNet-50의 top-1 accuracy를 75.3%에서 79.29%까지 개선시켰다고 한다. 또한, Image Classification 모델의 성능개선이 object detection이나 semantic segmentation과 같은 응용분야의 성능을 개선시킨다고 한다.
Introduction
AlexNet부터 시작하여 VGG, Inception 등 많은 모델들에 거쳐 Image Classification 분야의 성능은 개선되었다. 그러나, 이러한 성능개선은 모델 구조 뿐만 아니라 loss function의 변화, 데이터 전처리과정의 발전 등도 주요역할을 해왔다.
따라서, 저자는 모델 구조를 제안하는 것이 아니라 존재하는 trick들을 이용하여 성능을 개선하는 데에 집중했다. 그 결과, 아래 표와 같이 ResNet-50 모델이 모델 구조를 개선한 SE-ResNext-50보다 성능이 뛰어났다.

Training Procedures

1. Baseline Training Procedure
1 ) Training
- 이미지를 float32 데이터 타입을 가지는 텐서로 변환한다.
- 원본 이미지의 [ 8%, 100% ]의 크기를 [ 3/4, 4/3 ] 비율로 무작위 Crop을 진행한다. 그 이후, 이미지 크기를 224 x 224로 변환한다.
- 0.5의 확률로 좌우반전을 적용한다.
- hue, saturation, brightness를 [ 0.6, 1.4 ]의 균등 분포로부터 얻은 값으로 Scaling을 적용한다.
- PCA 노이즈를 $N(0, 0.1)$로부터 얻은 가중치와 함께 더한다 (아마도, AlexNet에서 진행한 것과 동일한 이야기인듯 하다).
- RGB 채널을 각각 [ 123.68, 116.779, 103.939 ]를 빼고, [ 58.393, 57.12, 57.375]로 나눔으로써 Normalization을 진행한다.
2 ) Validation
- 이미지의 비율을 유지하면서 Height와 Width 중 짧은것을 256으로 이미지 크기를 변환한다.
- 224 x 224로 Center Crop을 진행한다.
- Training의 6 )과 유사하게 Normalization을 진행한다.
3 ) Weight Initialization
- Weight는 Conv 레이어와 Linear 레이어 모두 Xavier Uniform initialization을 적용했다.
- Bias 값들은 모두 0으로 초기화 했다고 한다.
4 ) Batch Normalization
Batch Normalization을 적용하였고, $\gamma$는 1로, $\beta$는 0으로 초기화했다.
5 ) Optimizer
Optimizer는 Nesterov Accelerated Gradient를 적용했다.
6 ) Batch size & Learning rate & epoch
- Epoch은 120으로, Batch size는 256으로 설정했다.
- Learning rate는 0.1로 초기화했고, epoch이 30, 60, 90번째에서 10으로 나눠주었다.
2. Experiment Results
실험을 위해 ResNet-50, Inception v3, MobilNet을 사용했고, Inception v3는 이미지를 299 x 299로 변환했다.
결과는 아래 표와 같이 ResNet-50이 가장 좋았으며, Inception v3와 MobileNet은 학습 과정이 달라서 성능이 reference에 비해 약간 낮았다고 한다.

Efficient Training
1. Large batch training
배치 사이즈를 크게 설정하는 것은 수렴율을 감소시킨다고 한다. 즉, 같은 Epoch만큼 학습을 한다면 큰 배치 사이즈로 학습된 모델의. validation 정확도가 작은 배치 사이즈로 학습된 모델의 validation 정확도보다 낮다고 한다.
이러한 문제를 해결하기 위해서 논문에서는 다음과 같은 실험적 해결책을 제시한다.
1 ) Linear scaling learning rate
배치 사이즈를 키운다는 것은 gradient의 기댓값을 바꾸진 않지만, 분산은 줄이는 것과 동일하다. 다시 말해, 큰 배치 사이즈는 gradient의 노이즈를 줄인다는 것이고, 그러므로 조금 더 큰 learning rate로 초기화할 수 있다.
본 논문에서는 배치사이즈가 256일 때 learning rate를 0.1로 초기화하고, 더 큰 배치사이즈를 사용한다면 그에 비례하여 learning rate를 초기화한다 ( lr = 0.1 * batch_size / 256 ).
2 ) Learning rate warmup
학습 초기에는 랜덤 값으로 파라미터들이 초기화되기 때문에 최종 파라미터와는 차이가 있다. 따라서, 너무 큰 learning rate 초기화는 파라미터 학습을 방해한다. 따라서, learning rate 초기 값을 처음부터 사용하는 것이 아니라, 학습이 안정화되면 초기 값으로 돌아올 수 있게 설정한다. 이를 learning rate warm up이라 한다.
learning rate warm up의 방법은 간단하다. 예를 들어, 256개의 배치 개수가 존재하고, 첫 5 epoch동안 warm up을 진행하고 싶다면, learning rate를 $\dfrac {0.1 * i}{256 * 5}$로 설정하면 된다 (단, i는 1에서부터 256 * 5까지 증가).
3 ) Zero $\gamma$
ResNet 네트워크는 residual block으로 구성되어있다. residual block의 마지막에 BN 레이어가 존재한다면, 이 BN의 $\gamma$는 0으로 초기화시킨다.
4 ) No bias decay
Weight decay는 주로 weight와 bias 모두에 적용된다. weight decay는 overfitting을 방지하기 위해 weight에만 적용하는 것을 권장한다. 따라서, 논문에서는 BN의 파라미터와 모든 레이어의 bias는 정규화시키지 않았다고 한다.
2. Low-precision training
float32를 쓰든 float 16을 쓰든, 성능에 차이는 없는데 학습속도가 2~3배가량 증가했다고 한다.

3. Experiment Results
위의 표를 보면 ResNet-50을 기준으로 Batch size를 256, 32float을 사용했을 때 한 epoch당 13.3분이 걸린 것에 비해, float 16과 batch size를 1024로 했을 때 epoch당 4.4분이 걸렸다고 한다.
아래의 표를 보면 알 수 있지만, linear scaling만 사용하면 성능이 감소하는 것을 볼 수 있다.

Model Tweaks
1. ResNet Architecture

위 그림은 ResNet-50의 구조이다. 자세한 설명은 ResNet 논문에서 정리하였으므로 생략한다.
2. ResNet Tweaks
1 ) ResNet-B

ResNet-B는 ResNet의 downsampling block을 위와 같이 수정한다. 즉, stride 위치를 바꾼다.
2 ) ResNet-C

ResNet-C는 7 x 7 Conv를 3개의 3 x 3 Conv로 교체한 것이다.
3 ) ResNet-D

ResNet-D는 Path B의 1 x 1 Conv연산 전에 AvgPool을 추가시킨다.
3. Experiment Results

결과를 보면, ResNet-D가 가장 우수한 성능을 낸다.
Training Refinements
1. Cosine Learning Rate Decay
Learning rate를 조절하는 것은 학습에 매우 중요하다. 이를 위해, 주로 특정 epoch마다 learning rate를 감소시키는 "step decay"를 주로 사용한다. 하지만, 본 논문에서는 Cosine Learning Rate Decay를 사용하여 주기함수형태로 learning rate를 조절한다.
아래 그림을 보면 알겠지만, step decay는 learning rate가 급감하는 반면, Cosine decay는 부드럽게 감소한다 (어느 것을 사용하든 성능에 큰 차이는 없는 것 같다).

2. Label Smoothing
label smoothing은 이전 Inception v2에서 이미 다뤘기때문에 생략한다.
3. Knowledge Distillation
Knowldege Distillation은 teacher 모델이 있고, student 모델의 loss와 teacher 모델의 loss가 penalty로 추가되어 학습이 진행된다. 즉, teacher 모델의 예측으로부터 얻은 라벨 분포 지식이 자식의 학습에 사용된다.

4. Mixup Training
Mixup은 Data Augmentation 기법 중 하나인데, 두가지의 이미지를 선형보간으로 섞어서 새로운 데이터를 만드는 것이다.

5. Experiment Results
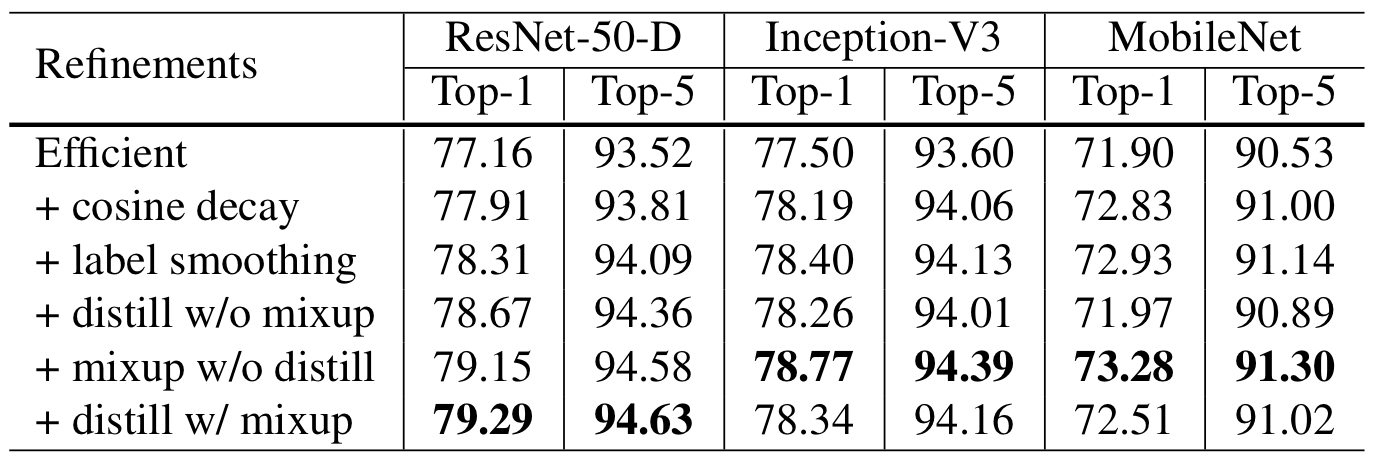
결과는 위와 같다. label smoothing을 위해 $\epsilon$을 0.1로 두고, distillation의 T를 20으로 두었다. 그리고, ResNet-152-D를 teacher 모델로 설정하였다.
Transfer Learning
1. Object Detection

Object detection 모델로써 Faster R-CNN을 사용하였고, 결과는 위와 같다.
2. Semantic segmentation

Semantic segmentation 모델로써 FCN을 사용하였고, 결과는 위와 같다.
Discussion
ResNet-D는 모델링이라기보단 다양한 트릭들을 사용하여 성능을 개선시켰다.
'Classification' 카테고리의 다른 글
| [논문 정리] MobileNet v3 (0) | 2022.12.22 |
|---|---|
| [논문 정리] MobileNet v2 (0) | 2022.12.17 |
| [논문 정리] ShuffleNet v2 (1) | 2022.12.17 |
| [논문 정리] MobileNet v1 (0) | 2022.12.15 |
| [논문 정리] NasNet (0) | 2022.12.14 |



