
- Convolution 종류
- SPP-Net
- LeNet 구현
- Optimizer
- 딥러닝
- image classification
- object detection
- deep learning
- Weight initialization
- overfeat
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Today
- Total
I'm Lim
[논문 정리] MobileNet v1 본문
Paper
Howard, Andrew G., et al. "Mobilenets: Efficient convolutional neural networks for mobile vision applications." arXiv preprint arXiv:1704.04861 (2017).
Abstract
MobileNet은 depthwise seperable convolution을 이용하여 모델을 가볍게 만들었다.
MobileNet Architecture
1. Depthwise Separable Convolution
1 ) 기존의 CNN 연산의 컴퓨터 계산량은 다음과 같다.


여기서 $D_k$는 커널의 크기이고, $N$은 출력 채널의 개수이며, $M$은 입력 채널의 개수, $D_F$는 feature map의 크기이다.
2 ) Depthwise Convolution의 컴퓨터 계산량은 다음과 같다.
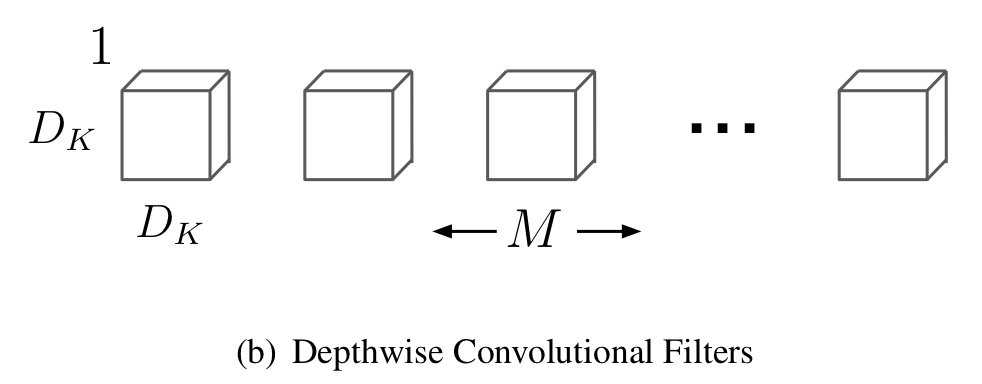

각 feature map에 대한 spatial convolution이므로 입력 채널의 개수와 입력 채널의 feature map, 커널의 크기만이 관여함을 볼 수 있다.
3 ) Pointwise Convolution의 컴퓨터 계산량은 다음과 같다.


각 채널에 대한 channel convolution이므로 입력 feature map의 개수와 입력 채널의 수, 그리고 출력 채널의 수만이 관여함을 볼 수 있다.
따라서, depthwise seperable convolution의 계산량을 standard convolution의 계산량으로 나누면 아래와 같고, 이는 3 x 3 Conv진행시 거의 9배에 가까이 계산량이 줄어든다고 한다.

2. Network Structure and Training

MobileNet의 구조는 위와 같고, dw는 depthwise를 의미한다. 또한, 마지막 FC 레이어를 제외하고는 BN과 ReLU를 뒤에 붙였다고 한다.
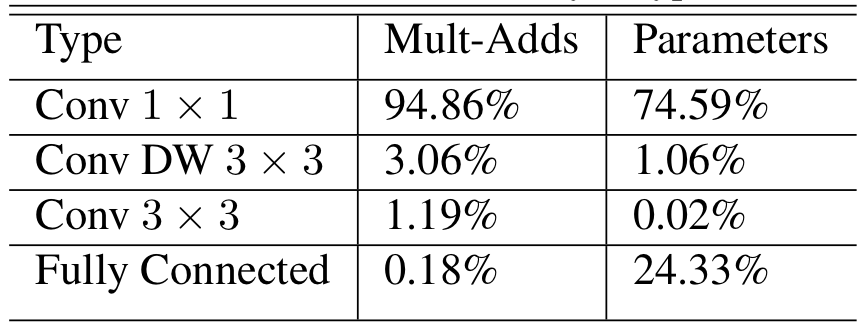
위 표를 통해, MobileNet의 파라미터와 계산량은 대부분 1 x 1 Conv에 몰려있음을 알 수 있다.
학습을 위해, Inception v3에서 그랬듯이 RMSprop을 사용하였다고 한다. 하지만, 작은 모델은 Overfitting의 가능성이 적기 때문에 data augmentation이나 regularization을 조금만 사용하였다고 한다.
3. Width Multiplier: Thinner Models
비록 MobileNet이 작은 모델이지만, 종종 더욱 작은 모델을 요구하는 경우가 많다. 더욱 작은 모델을 만들기 위해서 width multiplier라고 불리는 $\alpha$라는 하이퍼 파라미터를 사용하였다. 이 하이퍼 파라미터는 각 레이어의 채널의 수를 $\alpha$의 비율만큼 곱하는 역할을 한다. 즉, 입력 채널의 수 $M$이 $\alpha M$이 되게 한다.
당연하게도, $\alpha$는 (0, 1] 사이의 범위를 가지며, 주로 1, 0.75, 0.5, 0.25를 사용한다.
4. Resolution Multiplier: Reduced Representation
또 다른 하이퍼 파라미터로는 $\rho$가 있는데, 이는 feature map 크기를 일괄적으로 줄이는 역할을 한다.
당연하게도, $\rho$ 역시 (0, 1] 사이의 범위를 가지며, 주로 224, 192, 160 혹은 128을 사용한다.
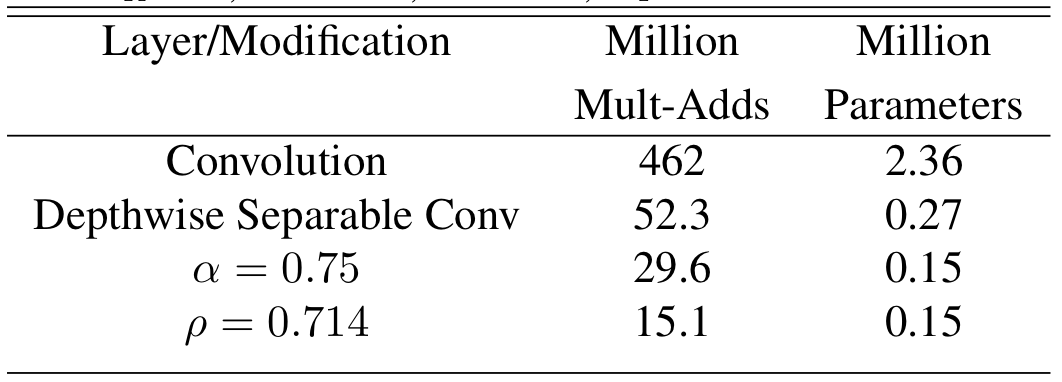
위의 표는 $\alpha$와 $\beta$를 설정하였을 때의 모델 계산량과 파라미터 수를 나타낸다.
Experiments
1. Model Choices

위 표는 depthwise seperable convolution을 사용한 MobileNet이 Full convolution을 사용한 Mobile보다 성능은 1% 낮지만 파라미터의 수와 계산량을 훨씬 많이 낮춤을 보여준다.

위 표는 기존 MobilNet에서 14 x 14 x 512 feature map 크기를 갖는 레이어를 제거한 Shallow MobileNet과 width multiplier $\alpha$를 0.75로 설정한 MobileNet의 성능을 비교한 결과이며, 그 결과 width multiplier를 줄임으로써 파라미터 수를 줄이는 것이 성능유지에 더욱 유리했음을 보여준다.
2. Model Shrinking Hyperparameters

위 표는 width multiplier 하이퍼 파라미터를 바꿔가며 성능을 비교하였는데, 모델이 너무 작은 $\alpha$ = 0.25를 제외하면 성능이 급격히 감소하진 않았다.

위 표는 resolution multiplier 하이퍼 파라미터를 바꿔가며 성능을 비교하였는데, $\rho$가 감소함에 따라, 성능이 급격히 감소하진 않았다.
Discussion
MobileNet은 depthwise separable convolution을 이용하여 모델의 파라미터 수와 계산량을 줄인 효율적인 (efficient) 모델이다. MobileNet은 SOTA는 달성하진 못하였지만, 파라미터 수 대비 성능을 생각한다면 굉장히 효율적이라고 볼 수있다.
'Classification' 카테고리의 다른 글
| [논문 정리] MobileNet v2 (0) | 2022.12.17 |
|---|---|
| [논문 정리] ShuffleNet v2 (1) | 2022.12.17 |
| [논문 정리] NasNet (0) | 2022.12.14 |
| [논문 정리] CondenseNet (0) | 2022.12.12 |
| [논문 정리] SENet (0) | 2022.12.12 |



