
- image classification
- Optimizer
- overfeat
- Weight initialization
- LeNet 구현
- Convolution 종류
- deep learning
- SPP-Net
- object detection
- 딥러닝
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Today
- Total
I'm Lim
[논문 정리] ShuffleNet v2 본문
Paper
Ma, Ningning, et al. "Shufflenet v2: Practical guidelines for efficient cnn architecture design." Proceedings of the European conference on computer vision (ECCV). 2018.
Abstract
Image Classification 모델들의 계산 복잡도의 평가지표로 FLOPs를 주로 사용하는데 이는 간접적인 평가지표이고, 직접적인 평가지표인 Speed는 메모리 접근 시간이나 플랫폼의 특성에 의존한다. 따라서, 이 논문에서는 특정 플랫폼에서 직접적인 평가지표를 이용하여 평가하는 것을 목표로 하였다.
Introduction
Image Classification 모델의 또 다른 중요한 요소 중 하나는 계산 복잡도다. 이 계산 복잡도를 측정하는 평가지표로써, FLOPs가 자주 사용되었는데 speed나 latency같이 직접적인 평가지표는 아니다. 단적인 예로 MobileNet v2는 NasNet-A보다 훨씬 빠른데 FLOPs는 비슷하다고 한다.
이러한 현상이 발생하는 이유는 크게 2가지를 들 수 있다.
1 ) Speed에 영향을 끼치는 여러가지 중요한 요소가 FLOPs에는 고려되지 않는다.
2 ) 플랫폼에 따라 같은 FLOPs를 가지더라도 다른 running time을 갖는다.
이러한 이유로 논문에서는 효율적인 모델의 정의를 위해 1 ) Speed와 같은 직접적인 평가지표를 사용해야 하고, 2 ) 같은 플랫폼 (논문에서는 ARM과 GPU를 사용)에서 비교를 해야한다고 하였다.
Practical Guidelines for Efficient Network Design
G1. Equal channel width minimizes memory access cost (MAC)
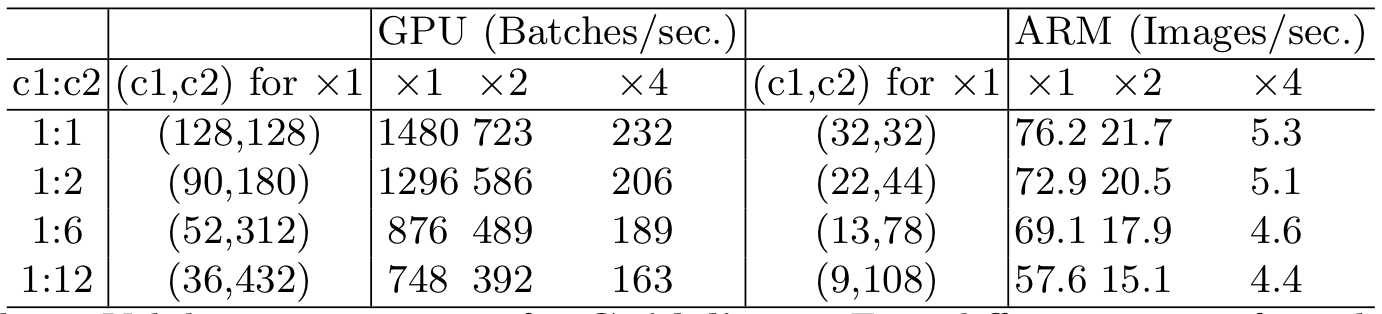
간단히 말하면, 1 x 1 Conv연산의 입력 채널의 수와 출력 채널의 수의 비율이 1 : 1일 때, 계산속도가 가장 빨랐다고 한다.
G2. Excessive group convolution increases MAC
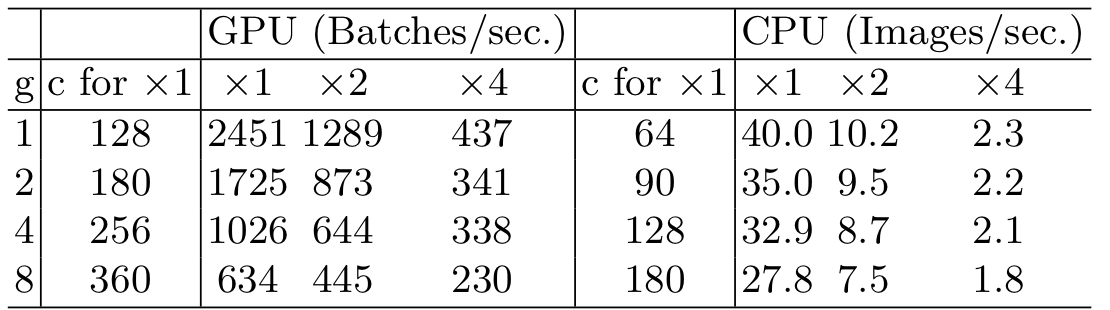
간단히 말하면, group의 개수를 늘리는 것이 계산속도를 낮춘다고 한다. 따라서, 채널의 수를 키움으로써 성능을 높이는 이익보다 계산속도 저하에 따른 불이익이 더 클 수 있으므로 group의 개수는 상당히 유의해서 다루어야한다고 한다.
G3. Network fragmentation reduces degree of parallelism

GoogLeNet이나 NasNet을 생각해보면 한 블록 내에 여러개의 Conv 연산이 연결됨을 알 수 있다. 이를 논문에서는 Network fragmentation이라 한다. 이러한 구조는 성능을 높이지만 GPU의 효율을 낮춘다고 한다.
결과를 보면, 4 fragment 구조가 1 fragment구조에 비해 3배가량 느린 것을 알 수 있다.
G4. Element-wise operations are non-negligible
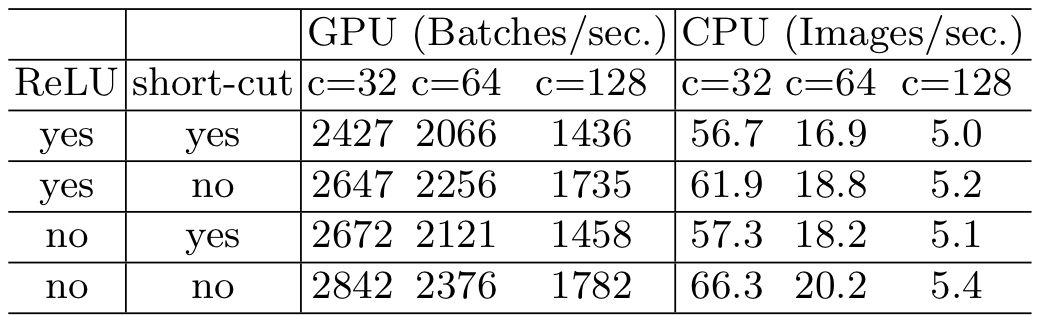
FLOPs 계산할 때는 고려되지 않는 short-cut connection이라든지, non-linearity 연산 역시 계산속도에 무시할 수 없는 영향을 끼친다. 결과를 보면 ReLU와 shortcut connection을 모두 제거했을 때, 대략 20%의 계산속도 개선이 이루어졌음을 알 수 있다.
ShuffleNet v2
1. Review of ShuffleNet v1
ShuffleNet v1은 pointwise group convolution과 bottleneck structure를 사용한다. 이는 G1과 G2를 위배한다. 또한, 너무 많은 group의 수를 둔다면 G3를 위배하게 되고, ShuffleNet unit의 마지막에서 element-wise addsms G4를 위배한다.
2. Channel Split and ShuffleNet v2

ShuffleNet v1의 문제를 해결하기 위해, ShuffleNet v2는 channel split을 사용했다 (그림 c).
1 ) Channel split을 통해, 입력 채널은 $c`- c$의 채널과 c의 채널을 가진 두개의 브랜치로 나뉜다. 그리고, 한쪽 브랜치는 어떠한 연산도 하지 않는다 (G3). 또한, 논문에서는 $c` = c / 2$로 설정했다.
2 ) 나머지 한쪽 브랜치는 출력 채널의 수가 입력 채널의 수과 동일하다 (G1). 그리고, Channel split에서 이미 그룹이 나뉘어졌기 때문에 1 x 1 Conv연산은 더이상 group convolution이 아니다 (G2).
3 ) 두 브랜치가 concatenate되며 channel shuffle의 과정을 거친다.
Down sampling을 위해서는 그림 d를 사용하는데, channel split을 하지 않는다. 그러므로, 채널의 수가 두배가 된다.
위와 같은 블록으로 ShuffleNet v2는 이루어지고, 모델의 구조는 아래와 같다.
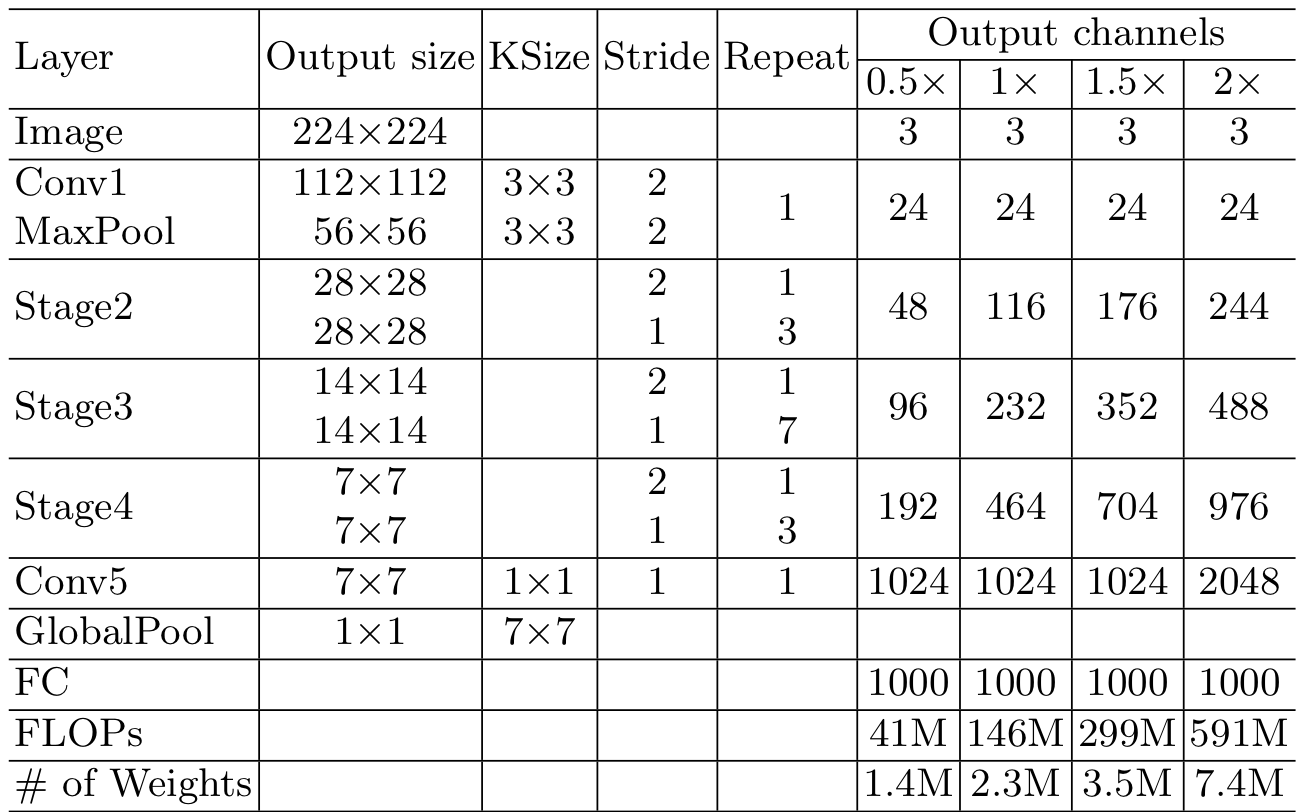
Experiment
실험을 위해, 비교모델들의 계산 복잡도를 40, 140, 300, 500 MFLOPs로 수정하고, ShuffleNet v2와 비교를 하였다. 여러 실험을 진행하였지만, 요약하자면 ShuffleNet v2가 같은 계산 복잡도일 때 타 모델보다 우수한 성능을 보인다.
Discussion
ShuffleNet v2는 간접적인 계산 복잡도 평가지표인 FLOPs를 줄이기 위해 고안된 ShuffleNet v1을 직접적인 계산 복잡도 평가지표인 Speed를 높이기 위해 수정한 모델이다.
'Classification' 카테고리의 다른 글
| [논문 정리] ResNet-D (0) | 2022.12.17 |
|---|---|
| [논문 정리] MobileNet v2 (0) | 2022.12.17 |
| [논문 정리] MobileNet v1 (0) | 2022.12.15 |
| [논문 정리] NasNet (0) | 2022.12.14 |
| [논문 정리] CondenseNet (0) | 2022.12.12 |



