
- image classification
- Convolution 종류
- Optimizer
- SPP-Net
- overfeat
- deep learning
- LeNet 구현
- 딥러닝
- object detection
- Weight initialization
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Today
- Total
I'm Lim
Momentum / Nesterov Accelerated Gradient 본문
Paper
Ruder, Sebastian. "An overview of gradient descent optimization algorithms." arXiv preprint arXiv:1609.04747 (2016).
논문이 가지는 의미
다양한 optimization 기법을 통해 어떠한 이유로 optimization이 발전해왔는지에 대해 고찰해볼 수 있다. 또한, 어떤 optimization 기법을 사용해야 될지에 관한 직관을 키울 수 있다.
1. Momentum

Gradient Descent 글에서도 설명했다시피 BGD, SGD, Mini-batch GD는 local minimum이나 saddle point를 잘 빠져나오지 못한다. 이는 다시말해 손실함수가 global minimum으로 도달하지 못해 성능 저하를 야기할 수 있다. 따라서, 이 문제를 해결하기 위해 Momentum Optimizer가 고안되었다.
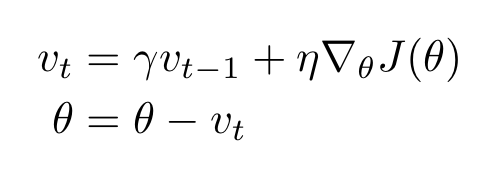
파라미터
- $v_{t}$ : 모멘텀
- $\theta$ : 가중치 파라미터
하이퍼 파라미터
- $\eta$ : learning rate로써 계산된 loss function의 gradient를 얼만큼 weight 업데이트시 반영할 것인가를 결정하는 파라미터
- $\gamma$ : 모멘텀을 얼마나 고려할지에 관한 파라미터
Momentum 특징
Momentum은 이전 기울기의 속도를 고려한다. 이 값은 $v_{t}$에 누적된다.
Momentum 장점
기울기의 속도를 (혹은 관성) 가중치 업데이트에 고려함으로써 local minimum과 saddle point에서 더 잘 벗어나게 해준다.
Momentum 단점
Momentum의 단점은 global minimum에서도 이 관성이 작용한다는 점이다. 그래서 global minimum도 벗어날 가능성을 가진다.
2. Nesterov Acclearted Gradient ; NAG
Gradient Descent 글에서도 설명했다시피 BGD, SGD, Mini-batch GD는 local minimum이나 saddle point를 잘 빠져나오지 못한다. 이는 다시말해 손실함수가 global minimum으로 도달하지 못해 성능 저하를 야기할 수 있다. 따라서, 이 문제를 해결하기 위해 Momentum Optimizer가 고안되었다.

파라미터
- $v_{t}$ : 모멘텀
- $\theta$ : 가중치 파라미터
하이퍼 파라미터
- $\eta$ : learning rate로써 계산된 loss function의 gradient를 얼만큼 weight 업데이트시 반영할 것인가를 결정하는 파라미터
- $\gamma$ : 모멘텀을 얼마나 고려할지에 관한 파라미터
NAG 특징
NAG는 Momentum과 달리 모멘텀 스텝을 먼저 진행하고, 해당 위치에서 기울기를 구해 가중치를 업데이트 시킨다.
NAG 장점
모멘텀 스텝을 먼저 진행하고, 가중치를 업데이트 시키기 때문에 Momentum의 장점 중 하나인 빠른 이동의 장점은 유지하면서도 global minimum을 지나치는 단점을 보완하였다고 볼 수 있다.
NAG vs Momentum

Momentum과 Nesterov Accelerated Gradient의 차이를 설명할 때 항상 사용되는 그림인데 개인적으로 한번에 와닿진 않았다.
우선, 모멘텀을 3 step 진행하겠다.
1 step.
$v_1 = \gamma v_0 + \eta \nabla_{\theta} J(\theta_0)$
$\theta_1 = \theta_0 - v_1$
2 step.
$v_2 = \gamma v_1 + \eta \nabla_{\theta} J(\theta_1)$
$\theta_2 = \theta_1 - v_2$
3 step.
$v_3 = \gamma v_2 + \eta \nabla_{\theta} J(\theta_2)$
$\theta_3 = \theta_2 - v_3$
파란색 식을 정리하면 $\theta_2 = \theta_1 - v_2 = \theta_1 - \gamma v_1 - \eta \nabla_{\theta} J(\theta_1)$ 가 된다.
이때, $\theta_1$ 는 빨간색 점에, $-\gamma v_1$부분은 momentum step에, $-\eta \nabla_{\theta} J(\theta_1)$ 부분이 gradient step에 해당하게 된다. 따라서, 윗 그림에서 왼쪽이 Momentum update에 해당하는 그림이다.
다음으로, Nesterov Accelerated Gradient를 3 step 진행하겠다.
1 step.
$v_1 = \gamma v_0 + \eta \nabla_{\theta} J(\theta_0 - \gamma v_0)$
$\theta_1 = \theta_0 - v_1$
2 step.
$v_2 = \gamma v_1 + \eta \nabla_{\theta} J(\theta_1 - \gamma v_1)$
$\theta_2 = \theta_1 - v_2$
3 step.
$v_3 = \gamma v_2 + \eta \nabla_{\theta} J(\theta_2 - \gamma v_2)$
$\theta_3 = \theta_2 - v_3$
파란색 식을 정리하면 $\theta_2 = \theta_1 - v_2 = \theta_1 - \gamma v_1 - \eta \nabla_{\theta} J(\theta_1- \gamma v_1)$ 가 된다.
이때, $\theta_1$ 는 빨간색 점에, $-\gamma v_1$부분은 momentum step에, $-\eta \nabla_{\theta} J(\theta_1- \gamma v_1)$ 부분이 gradient step에 해당하게 된다. 따라서, 윗 그림에서 오른쪽이 Nesterov update에 해당하는 그림이다.
$-\eta \nabla_{\theta} J(\theta_1- \gamma v_1)$ 부분을 조금 더 살펴보면, $\theta_1$ 부분에서 momentum step $- \gamma v_1$만큼 이동시킨 후, 그 지점에서 기울기를 구한다는 뜻이다. 따라서, Nesterov update는 Momentum step을 먼저 이동하고, 기울기를 구한다는 것을 알 수 있다.
마지막으로, 그림에서 빨간색 지점을 global minimum이라 가정하여 두 Optimizer를 고려해본다면 Momentum은 global minimum은 관성에 의해 튕겨 나갈 가능성이 크지만, Nesterov는 Momentum step의 반대방향으로 gradient step을 진행하여 이 가능성을 줄인다.
'Deep Learning > Optimization' 카테고리의 다른 글
| Adam Optimizer (0) | 2022.09.28 |
|---|---|
| AdaGrad / AdaDelta / RMSprop (0) | 2022.09.26 |
| Gradient Descent (0) | 2022.09.18 |
| Optimizer (0) | 2022.08.09 |



