
- overfeat
- Weight initialization
- Optimizer
- Convolution 종류
- object detection
- 딥러닝
- SPP-Net
- deep learning
- image classification
- LeNet 구현
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Today
- Total
I'm Lim
[논문 정리] Inception v2, v3 본문
Paper
Szegedy, Christian, et al. "Rethinking the inception architecture for computer vision." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Abstract
AlexNet에서부터 GoogLeNet에 이르기까지 딥러닝 모델링의 방향성은 모델의 크기와 컴퓨터 계산비용을 늘림으로써 성능을 향상시키는 것이었다. 하지만, 계산비용과 파라미터 개수를 줄이는 것은 모바일 환경에서의 사용과 빅데이터 상황에서 유용하게 작용할 것이다.
본 논문에서는 위를 근거로 컴퓨터 계산 비용을 줄이는 연구를 진행할 뿐만 아니라 Regularization을 적극적으로 사용하여 또다시 Top-1 Error rate와 Top-5 Error rate를 갱신하였다.
Introduction
LeNet에서부터 출발하여 GoogLeNet에 이르기까지 Image Classification 분야에서 딥러닝 모델은 모델링의 개선을 통하여 성능을 계속 갱신해왔다. 한가지 흥미로운 점은 Image Classification 분야에서의 성능 개선은 다른 Computer Vision 분야 (e.g, Object Dectection, Image Segmentation) 에서도 성능을 개선시킨다는 것이다.
VGGNet은 GoogLeNet과 성능은 거의 유사했으나, AlexNet에 비해 파라미터 수가 3배가 많았다. 그에 비해, GoogLeNet은 AlexNet에 비해 파라미터 수가 12배가 적었다. ( # of parameters : AlexNet = 60M, VGGNet = 180M, GoogLeNet : 5M )
본 논문은 GoogLeNet에서 컴퓨터 계산비용과 파라미터 개수를 줄이는 것을 목표로 하였다.
General Design Principles
본 논문에서는 일반적인 모델링을 위하여 몇가지 제안을 하였다.
1. 네트워크 초반부에 Pooling을 남용하면, 정보량을 감소시키므로 가급적 피할 것.
네트워크 초반부에 representational bottleneck의 사용을 피한다. (representational bottleneck이란 Pooling을 통하여 입력이 가지고 있던 정보량을 감소시키는 행위를 뜻한다.).
2. 고차원을 가진 표현은 네트워크 내에서 처리되기 쉽다.
한 네트워크 내에서 고차원의 표현이 더욱 처리되기 쉽다. 또한, 네트워크내 Conv Layer를 잘게 쪼갬으로써 activation의 개수를 늘리는 것이 조금 더 분리된 feature를 추출하는데 도움이 된다.
3. Channel Reduction을 적절히 사용하자.
Spatial aggregation 전에 Channel reduction을 사용하여 큰 정보 손실없이 저차원의 채널로 임베딩시킬 수 있다. 본 논문에서는 인접한 유닛들 간에는 강한 상관관계가 존재하기때문에 Spatial aggregation 이전에 channel reduction을 수행하는 것이 큰 정보 손실을 야기하진 않을 것이라고 가설을 세웠다. Channel Reduction을 사용할 때, 모델이 더욱 빨리 학습하였다고 한다.
4. 네트워크의 깊이와 폭의 밸런스를 유지하라.
물론 이론적으로 폭과 깊이를 둘 다 늘리면 성능이 개선되겠지만, 실제로는 메모리의 한계 등을 이유로 불가능하다. 이러한 상황에서 가장 최적으로 성능을 개선시키는 방법은 네트워크의 깊이와 폭의 밸런스를 유지했을 때라고 한다.
Facorizing Covolutions with Large Filter Size
1. Factorization into smaller convolutions
VGG 논문에서도 이미 살펴봤듯이 5 x 5 Convolution 연산을 1번 수행하는 것보다 3 x 3 Convolution 연산을 2번 수행하는 것의 계산량이 더 적다. 이렇게 계산량을 줄이는 것은 올바른 방향인 듯하다.

2개의 3 x 3 Convolution 연산에 첫 번째 3 x 3 Convolution 연산에 activation function을 적용시키는 것이 옳은 것일까? 논문에서는 이를 해결하기 위해 실험을 진행하였고, 결론적으로 activation function을 사용하는 것이 좋다고 결론지었다.


2. Spatial Factorization into Asymmetric Convolutions
3 x 3 Convolution을 사용하면 5 x 5 Convolution과 7 x 7 Convolution과 같이 Kernel size : 3n-1 을 표현할 수 있다. 그러면 더 작은 Kernel Size를 가지는 2 x 2 Convolution을 사용하면 되는거 아닐까? 같은 논리로 2n-1 Kernel Size를 표현할 수 있으니깐 말이다.
물론 사용할 수 있을 것이다. 그러나, 2 x 2 Convolution보다는 n x 1과 같이 비대칭적인 Convolution을 수행하는 것이 훨씬 나았다고 한다. 따라서, 논문에서는 n x n Convolution을 표현하기 위해 1 x n Convolution 이후 n x 1 Convolution을 수행하였다고 한다.
실제로 이 Asymmetric Convolution은 초기 레이어에서는 잘 동작하지 않았고, feature map의 크기가 12에서 20 사이일 때 가장 잘 동작했다고 한다.

Utility of Auxiliary Classifiers
GoogLeNet 논문에서는 Auxiliary Classifier가 vanishing gradient problem을 해결하기 위해서 사용되었다고 한다. 하지만, 실험적으로 이것은 사실이 아니었다고 한다. 그 대신, regularizer로써의 역할을 한다고 주장한다.
Efficient Grid Size Reduction
전통적으로, CNN 모델들은 feature map 크기를 줄이기 위해서 Pooling을 사용해왔다. 하지만, representation bottleneck을 방지하기 위해 pooling 이전에 채널을 키우는 것이 일반적이다.
아래 그림처럼 d x d 크기의 채널의 개수가 k개인 featuremap이 있다고 하자. 위 연산을 거치기 위해 필요한 파라미터 수는 $2d^2k^2$ 가 된다. 이 계산량을 줄이기 위해 Pooling 이후에 1 x 1 Convolution을 거친다면 요구되는 파라미터의 수는 $2 (\dfrac {d}{2})^2 k^2$ 가 된다. 하지만 이러면 representational bottleneck을 방지하지 못한다.

그 대신, 논문에서는 아래와 같이 stride를 2로 두고, Pooling과 Convolution 연산을 동시에 취한다.

Inception v2
위에서 설명한 것들을 종합하여 새로운 Inception 모듈을 만든다.

Inception v2는 42개의 레이어를 쌓았음에도 불구하고, GoogLeNet보다 2.5배정도의 computational cost를 가지고 VGGNet보다는 여전히 효율적이다.
Model Reularization via Label Smoothing
1. Cross Entropy : $q(k) = \delta_{k, y}$
Cross Entropy는 One-Hot Encoding을 가지는 실제 값과 확률을 나타내는 예측 값간의 NLL Loss로 이루어진다. 이러한 방식으로 학습을 하게되면 모델이 정답값만을 loss에 고려하여 학습하게 된다. 즉, 일반화 성능이 떨어지게 된다.
2. Label Smoothing : $q`(k) = (1 - \epsilon) \delta_{k, y} + \dfrac {\epsilon}{K}$
위의 문제를 해결하고자 논문에서는 정답이 아닌 라벨에도 일정한 값을 설정한다.
본 논문에서는 ImageNet 학습을 위해서 $u(k)$ : 1 / 1000, $\epsilon$ : 0.1로 설정하였다. 그 결과, top-1 error와 top-5 error 모두 0.2%만큼 줄였다고 한다.
Details of Learning
- Optimizer로 RMSProp에 decay를 0.9, epsilon : 1.0으로 설정하였을 때라고 한다.
- Learning rate를 0.045로 초기회하였고, 2 에폭이 지날 때마다 0.94를 곱하였다.
- Gradient가 2.0 이상이 되면 2.0으로 고정시켰다고 한다.
Performance on Lower Resolution Input
종종 작은 크기의 이미지를 학습시킬 때, 이미지 크기를 기존의 모델에 맞게 키우는 실수를 하곤 한다. 이는 더욱 어려운 task를 (작은 크기의 이미지를 분류, 인식이 더 어렵다) 더 연산량이 적은 모델로 (아마도 작은 크기의 이미지를 업샘플링시키는 건 인근 픽셀값들이 유사하므로 원래 큰 이미지를 연산하는 것보다 간단하다는 의미인듯 함) 풀려는 꼴이 된다. 당연히 말이 안되는 소리인 것이다.
따라서, 논문에서는 연산량을 고정시킨 후 실제로 높은 해상도가 성능에 얼만큼 영향을 미치는지 실험하고자 하였다.
실험을 위해 299 x 299, 151 x 151, 79 x 79 이미지를 사용하였다.
1. 299 x 299 이미지는 그대로 유지.
2. 151 x 151 이미지는 stride를 1로 바꾸고, max-pooling 사용
3. 79 x 79 이미지는 stride를 1로 바꾸고, max-pooling 제거

결과는 이미지의 크기와 관계없이 거의 유사했다.
하지만, 위처럼 모델을 세심히 수정하지 않고 그냥 입력 이미지의 크기에 맞게 네트워크 사이즈를 줄여버리는 것은 성능이 훨씬 안좋았다고 한다.
Experimental Results and Comparisons
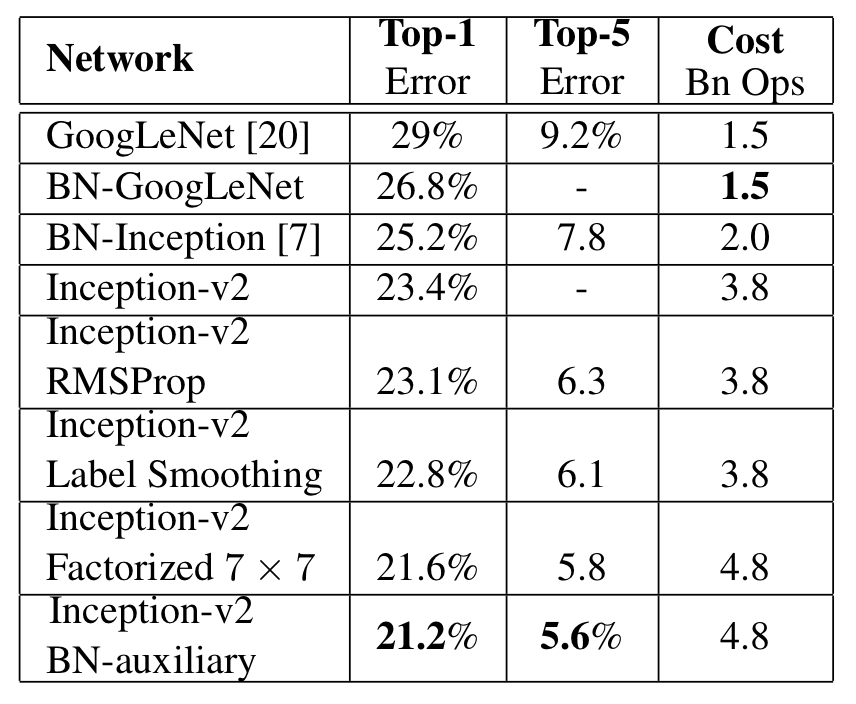
위 그림은 앞에서 설명했던 여러 기법들을 적용하였을 떄의 성능이다. Inception v2 라인들은 아래로 갈 때, 기법들이 누적해서 적용된다고 한다. BN-auxiliary는 GoogLeNet의 auxiliary classifier의 conv layer와 fc layer 모두 batch normalization을 적용시킨 것이다.
BN-auxiliary까지 모두 적용시킨 Inception v2를 Inception v3라고 한다.


Inception V3는 Single Model, Ensemble Model 전부에서 SOTA를 기록하였다.
Discussion
본 논문은 GoogLeNet의 후속연구로 모델링시에 Computational Cost에 집중하였다.
'Classification' 카테고리의 다른 글
| [논문 정리] Pre activation ResNet (0) | 2022.11.20 |
|---|---|
| [논문 정리] ResNet (0) | 2022.11.20 |
| [논문 정리] GoogLeNet ( Inception v1 ) (1) | 2022.11.11 |
| [논문 정리] VGGNet (0) | 2022.11.10 |
| [논문 정리] Network In Network (0) | 2022.11.07 |



