
- overfeat
- Optimizer
- image classification
- deep learning
- LeNet 구현
- 딥러닝
- SPP-Net
- object detection
- Weight initialization
- Convolution 종류
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Today
- Total
I'm Lim
[논문 정리] NasNet 본문
Paper
Zoph, Barret, et al. "Learning transferable architectures for scalable image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
Abstract
Image Classification 모델을 개발하는 것은 상당한 노력이 필요하다. 이 논문에서는 데이터 셋에 맞게 알아서 모델 구조를 학습하는 방법을 연구한다.
이러한 방식은 데이터 셋이 크다면 굉장히 오래걸리기 때문에 작은 데이터 셋에서 그 구조를 만들고, 큰 데이터 셋으로 확장한다고 한다. 작은 데이터 셋으로 CIFAR-10을 이용하였고, 이를 통해 찾은 모델 구조를 ImageNet으로 확장시켰다고 한다.
Neural Architecture Search는 모델 구조를 최적화시키기위해 강화학습을 이용한다. 이러한 방식을 CIFAR-10 데이터 셋에 적용시킨 모델을 NASNet이라고 하며, 이를 어떠한 수정없이 ImageNet 분류 문제에 적용시켰더니 SOTA를 달성하였다고 한다.
Method
Neural Architecture Search에서는 RNN이 서로 다른 구조의 자식 네트워크를 샘플링한다. 자식 네트워크들은 Validation 데이터 셋에 대해 어느정도의 성능을 보일 때까지 학습을 하고, 그 결과는 RNN이 더욱 좋은 모델을 생성하는 데에 사용된다. RNN의 가중치는 Policy Gradient에 의해 업데이트 된다 (Policy Gradient는 강화학습 알고리즘 종류 중 하나입니다).
위 내용을 그림으로 표현하면 아래와 같다.
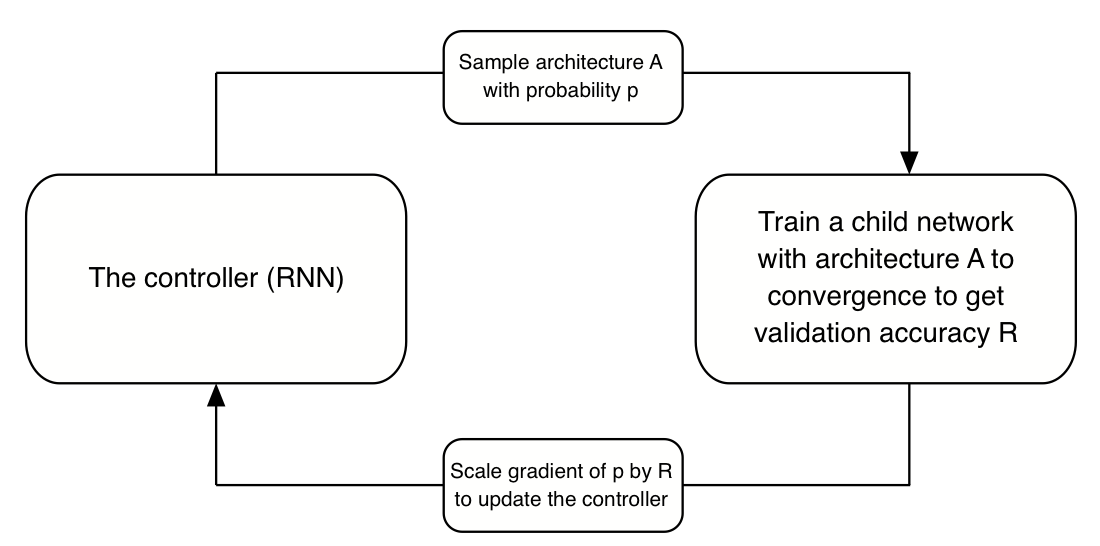
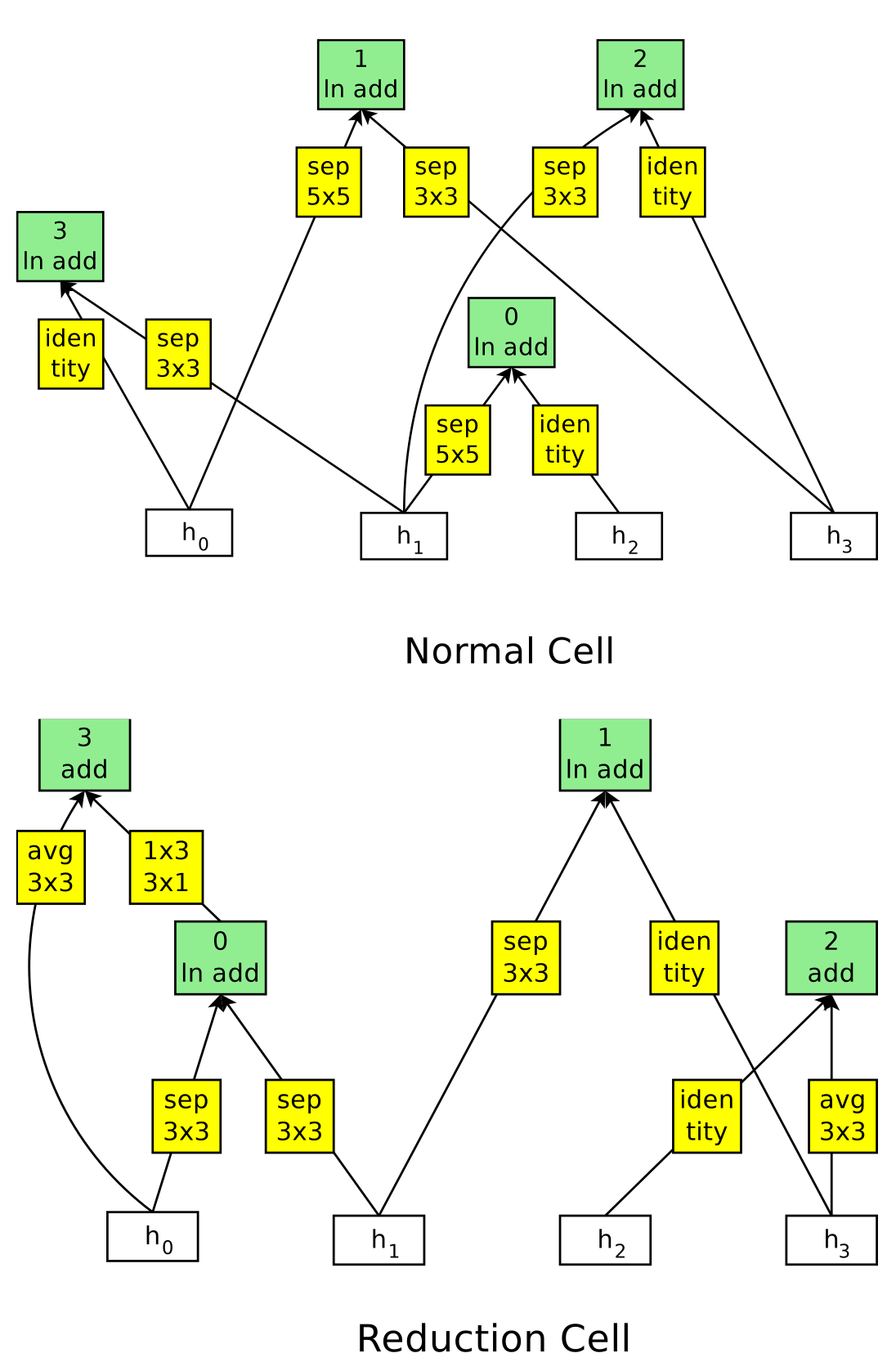
NASNet은 feature map 크기를 유지하는 1 ) Normal Cell과 feature map 크기를 절반으로 줄이는 2 ) Reduction Cell로 이루어진다. 즉, Nerual Search Architecture는 RNN을 이용하여 Normal Cell과 Reduction Cell을 찾는다.
1. Neural Architecture Seach 알고리즘
1 ) RNN이 $h_i$나 $h_{i-1}$ (혹은 더 이전에 생성된 hidden state)중 하나의 hidden state를 선택한다 .
2 ) Step 1과 동일하게 RNN이 두 번째 hidden state를 선택한다.
3 ) Step 1의 hiddens state에 어떠한 연산을 취할 것인지 결정한다.
4 ) Step 2의 hidden state에 어떠한 연산을 취할 것인지 결정한다.
5 ) Step 3와 Step 4의 출력을 결합하여 새로운 hidden state를 생성하기 위한 메소드를 선택한다.
위의 5가지 과정을 B번 반복한다. 논문에서는 이 B를 5로 지정하였다고 한다.
2. Step 3와 Step 4의 어떠한 연산
NAS 알고리즘의 Step 3와 Step 4에서 어떠한 연산을 취할 것인지 결정한다고 하였다. 만약에 이 "어떠한 연산"이 무한한 가능성을 가진다면 시간이 오래 걸릴 뿐더러 강화학습이 최적의 결과를 못찾을 가능성이 있다. 그렇기 때문에 이 "어떠한 연산"을 제한된 범위 내에서 선택하도록 하고, 이는 아래와 같다.

3. Step 5의 출력의 결합을 위한 메소드
NAS 알고리즘의 Step 5에서 출력을 결합하여 새로운 hidden state를 생성하기 위한 메소드를 선택한다고 하였다. 여기서, 결합을 위한 방법으로는 두 가지가 존재한다. 첫 번째는 element-wise addition, 두 번째는 concatenation이다.
사용되지 않은 hidden state들은 concatenated되어 마지막 셀의 출력에 제공된다고 한다.
4. RNN Controller
RNN controller가 Normal cell과 Reduction cell을 모두 예측하도록 하기위해, 저자는 간단하게 2 x 5B개의 예측을 하는 controller를 만들었다고 한다. 한 개의 5B는 Normal cell을 위한 것이고, 다른 하나의 5B는 Reduction cell을 위한 것이다.
Experimetns and Results
이번 섹션에서는 Architecture search의 과정을 실험한다. 모든 실험은 CIFAR-10 데이터 셋으로 진행되었고, RNN은 Proximal Policy Optimization으로 진행되었다 (GPU 500개를 사용했다고 한다...). 실험을 진행하여 제일 좋은 모델 3개를 뽑았는데 이를 NASNet-A, NASNet-B, NASNet-C라고 한다.


NASNet을 학습시킬 때, ScheduledDropPath를 이용하는 것이 좋다고 한다. 이는 DropPath의 수정버전이고, 일정확률로 path가 drop된다 (다만, ScheduledDropPath에서는 확률이 선형적으로 증가한다).
1. Results on CIFAR-10 Image Classification

학습을 위해서 N = 4 혹은 6으로 설정하였다. 보이다시피, CIFAR-10 데이터 셋에 대한 결과는 NASNet이 SOTA를 달성하였다.

2. Results on ImageNet Image Classification

ImageNet 데이터 셋을 학습시키기 위해서 단순히 CIFAR-10에서 사용한 구조를 가지고 와서 조금 수정만 하였다고 한다.


결과는 위와 같이 NASNet이 더욱 적은 파라미터 개수로 SOTA를 달성하였다.

제한된 컴퓨터 환경을 위해 고안된 모델들과 비교한 결과 역시 NASNet이 제일 좋은 성능을 기록하였다.
Improved features for object detection
이 챕터는 NASNet-A로 만들어진 Object detection 모델이 성능 개선에 도움이 되는지 확인한다. 이를 위해, COCO 데이터 셋과 Faster-RCNN을 이용하였다고 한다.

결과는 위와 같이 NASNet이 가장 우수함을 보였다.
Efficiency of architecture search methods

생각해보면 그냥 Random하게 모델을 생성해도 되지 않을까라는 의문이 든다. 이를 Random search라고 하는데 저자는 이것과 Reinforcement Learning search를 비교하였다. 위 그림을 보면, 강화학습을 이용하는 것이 random search보다 항상 좋음을 알 수 있다.
Discussion
NASNet이 SOTA를 달성한 것도 굉장히 놀라운 점이긴 하지만, Image Classification 모델링조차도 강화학습이 진행하고 이것이 인간이 심혈을 기울여 만든 모델의 성능을 이겼다는 점이 굉장히 놀랍다.
'Classification' 카테고리의 다른 글
| [논문 정리] ShuffleNet v2 (1) | 2022.12.17 |
|---|---|
| [논문 정리] MobileNet v1 (0) | 2022.12.15 |
| [논문 정리] CondenseNet (0) | 2022.12.12 |
| [논문 정리] SENet (0) | 2022.12.12 |
| [논문 정리] ShuffleNet v1 (0) | 2022.12.10 |



