
- image classification
- deep learning
- Weight initialization
- object detection
- SPP-Net
- overfeat
- Optimizer
- Convolution 종류
- 딥러닝
- LeNet 구현
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Today
- Total
I'm Lim
[논문 정리] ResNet 본문
Paper
He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Abstract
ResNet은 ILSVRC 2015 대회에서 우승한 모델로써 residual block이라는 이름의 모듈을 깊게 쌓은 모델이다. ResNet은 152개의 레이어 개수를 가진다. 이는 VGGNet보다 8배나 많은 레이어 개수고, 그럼에도 불구하고 ResNet은 lower complexity (파라미터 수가 적음)를 가진다.
Introduction
1. degradation problem
기존의 모델들은 레이어를 깊게 쌓는 것을 목표로 해왔다. 당연히, "Vanishing / Exploding gradient 가능성이 커지는거 아니야?"라는 질문을 할 수 있다. 다행스럽게도 Weight Initialization기법과 Batch Normalization 등으로 이러한 문제는 어느정도 해결되었다.
진짜로 문제가 되는 것은 degradation problem이다. degradation problem은 레이어를 깊게 쌓을수록 오히려 train / test error가 커지는 문제를 뜻한다. 이는, 레이어가 깊어질수록 train error는 작아지지만, test error가 커지는 Overfitting problem과는 다른 문제다.

따라서, 본 논문에서는 degradation problem을 해결하기위해 residual learning을 이용하였고, 이 모델이 ResNet이다.
2. Residual Block

- 기존의 모델들은 $F(x)$를 학습하는 반면, ResNet은 $F(x) + x$를 학습한다. 이 모델은 reference learning ($F(x) + x$)이 unreference learning ($F(x)$)보다 최적화하기 쉽다고 가설을 세웠다.
극단적인 예시로, identity mapping ($x$)가 최적이라면, reference learning에서는 $x = F(x) + x$가 될 것이고, $F(x)$가 0이 되면 된다. 그에 반해, unreference learning에서는 $F(x) = x$가 되어야 하는데, 이것이 더 어렵다는 것이다.
- Shortcut Connection이란 위 그림에서처럼 identity mapping (x)를 다음 레이어에 더해주는 것을 뜻한다.
Deep Residual Learning
1. Residual Learning
위에서 설명했듯이, Residual Learning은 $H(x) = F(x) + x$를 학습하게 된다. 그러면, $F(x) = H(x) - x$가 되고, 이를 residual (잔차)이라 한다. 생각해보면, x는 학습대상이 아니므로 위에서 나온 block은 결국 residual을 학습하게 된다. 따라서, 이를 residual learning이라 한다.
2. Identity Mapping by Shortcuts
Residual block을 수식으로 적으면 다음과 같다.
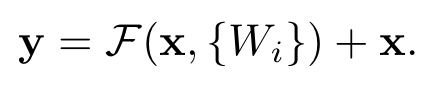
여기서, $x$와 $y$는 각각 레이어의 입력과 출력이다. $F$는 residual mapping에 해당하고, $x$는 identity mapping에 해당한다. 이 둘을 shortcut connection으로 더해주는데 이는 element-wise addition이다. 따라서, $F$와 $x$의 feature map 크기와 Channel의 개수는 동일해야한다.
- feature map의 크기를 맞추기 위해서 residual mapping 쪽 Conv 레이어에 Padding을 적용시킨다.
- channel의 개수를 맞추기 위해서 identity mapping에 linear projection을 적용시킨다.
3. Network Architecture

실험을 위해 VGG-19, VGG-style Plain Network, ResNet을 사용하였다고 한다. ResNet은 위에 설명한대로 Residual block으로 구성되었고, channel의 개수가 증가하면, Identity mapping에 Zero-padding이나 1 x 1 Convolution을 적용해 channel의 개수를 늘렸다고 한다. 두가지 경우 모두 feature map size를 줄이기 위해서 stride : 2를 적용한다.
Experiments
1. Plain Network vs ResNet

- 그림에서 보이다시피, Plain Network는 degradation problem이 발생하는 반면, ResNet에서는 발생하지 않았다.
- ResNet-34의 top-1 error는 25.03%로써, Plain-34보다 3.5%가량 낮았다. 이는 Residual Learning의 효율성을 입증한다.
- 18개의 레이어에서는 두 모델 모두 잘 수렴하였지만, ResNet이 수렴속도가 더 빨랐다.
2. Identity vs Projection shortcuts
위에서 Channel의 개수가 변하면 zero-padding이나 1 x 1 Convolution으로 채널의 개수를 늘릴 수 있다고 하였다. 이를 위해서 3가지의 모델을 실험하였다.
( A ) Channel의 개수를 늘릴 때만 zero-padding shortcut 사용 // 그 이외는 identity
( B ) Channel의 개수를 늘릴 때만 1 x 1 Conv shortcut 사용 // 그 이외는 identity
( C ) 모든 shortcut을 1 x 1 Conv로 사용

실험 결과, C가 성능이 가장 우수하였다고 한다.
3. Deeper BottleNeck Architecture
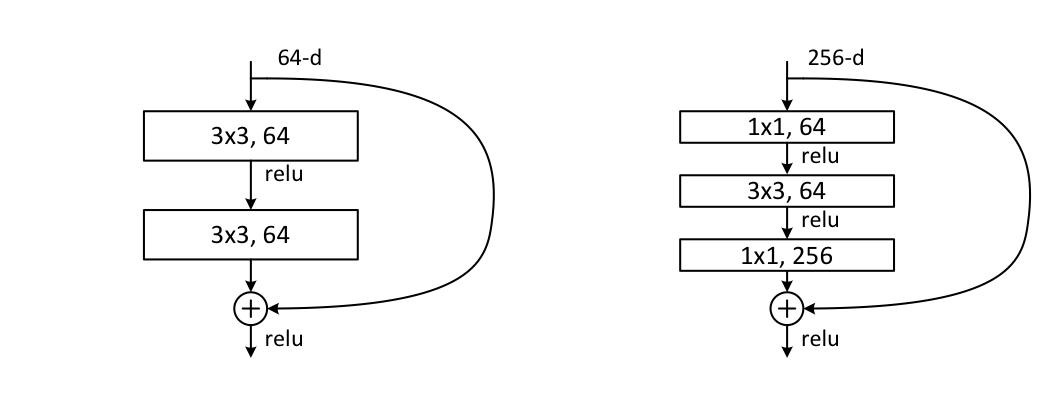
왼쪽 그림은 ResNet-34에 사용되는 Residual Block이고, 오른쪽은 ResNet-50, ResNet-101, ResNet-152에 사용되는 Residual Block이다.

ResNet-50을 구성하기 위해 기존 2개의 레이어를 갖는 Residual Block을 3개의 레이어를 갖는 Residual Block으로 교체하였다고 한다. 이 때, Channel을 늘리기 위해서 옵션 B를 사용하였다고 한다.
ResNet-101, ResNet-152를 구성하기 위해 3개의 레이어를 갖는 Residual Block을 사용하였다. 레이어가 상당히 깊음에도 불구하고, VGGNet보다 파라미터 수가 적었다.
Result
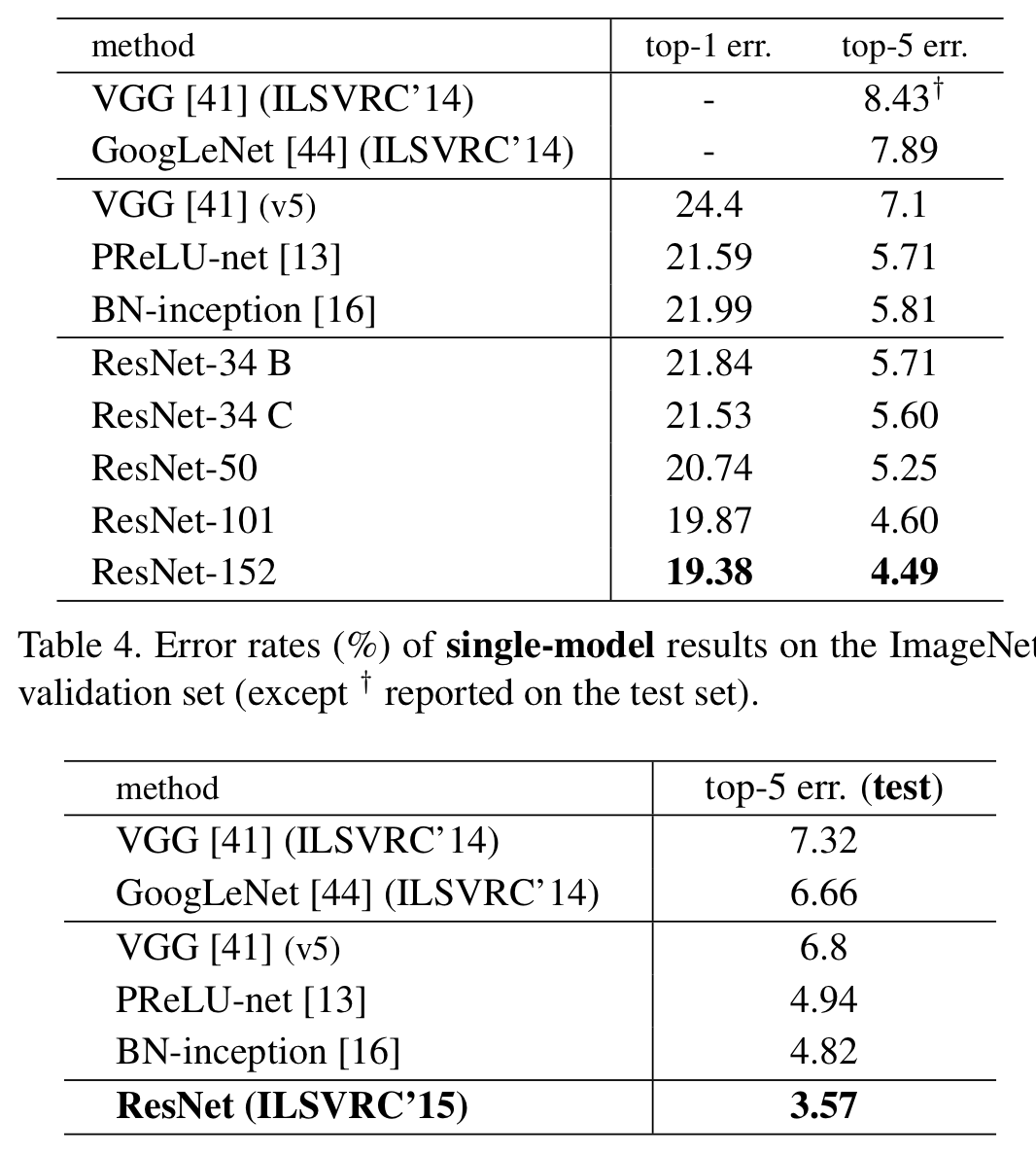
위 그림은 Single Model로 평가하였을 때 top-1 error와 top-5 error를 보여준다. 아래 그림은 Ensemble Model의 결과이다. 주목할만한 점은 ResNet-152 Single Model의 error가 기존의 ensemble model들의 결과를 모두 제쳤다는 것이다.
Ensemble Model을 위해 6개의 다른 레이어 깊이를 갖는 모델들을 사용하였다고 한다.
Details of Learning
1. 데이터 셋은 ImageNet을 사용하였다.
2. Data Augmentation
- Sampling을 위해서는 VGGNet에서 사용한 rescale할 크기를 S = [256, 480] 범위로 지정해놓는 방식을 사용하였다.
- 224 x 224 크기로 Random Crop 하고, Random horizontal flip도 적용하였다고 한다.
3. 전처리는 AlexNet에서 사용한 기법들을 사용했다.
4. Optimizer는 momentum을 0.9로 설정한 SGD를 사용하였고, batch size는 256를 사용하였다.
5. Learning rate는 0.1로 초기화되었고, validation loss가 줄어들지 않는다면 10으로 나눠주었다고한다.
6. Weight decay를 0.0001로 두었다.
7. Test
- 테스트를 위해서는 AlexNet처럼 모서리 4개, 중앙 이미지를 Crop하고, 여기에 Horizontal flip을 적용한 총 10개의 사진을 사용했다고 한다.
- 성능을 높이기 위해, VGGNet처럼 Fully Convolution Net으로 바꾸고, Multi-scale Evaluation을 진행하였다.
'Classification' 카테고리의 다른 글
| [논문 정리] Inception v4 (0) | 2022.11.20 |
|---|---|
| [논문 정리] Pre activation ResNet (0) | 2022.11.20 |
| [논문 정리] Inception v2, v3 (0) | 2022.11.20 |
| [논문 정리] GoogLeNet ( Inception v1 ) (1) | 2022.11.11 |
| [논문 정리] VGGNet (0) | 2022.11.10 |



