
- 딥러닝
- image classification
- overfeat
- object detection
- Convolution 종류
- LeNet 구현
- Optimizer
- SPP-Net
- Weight initialization
- deep learning
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Today
- Total
목록deep learning (27)
I'm Lim
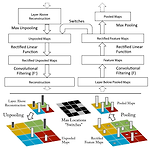 [논문 요약] ZFNet
[논문 요약] ZFNet
1. Paper Zeiler, Matthew D., and Rob Fergus. "Visualizing and understanding convolutional networks." European conference on computer vision. Springer, Cham, 2014. 2. Introduction 이 논문은 ILSVRC 2012 우승을 차지한 AlexNet 모델을 분석합니다. AlexNet 모델의 성능이 굉장히 좋은 것은 사실이지만, 왜 그런지에 대한 설명은 없고, 그렇기 때문에 성능 개선시킬 수 있는지도 알 수 없습니다. 이 논문에서는 그 이유에 대해 분석하고, 모델을 개선시킴으로써 AlexNet보다 우수한 성능을 달성했습니다. 3. Visualization with a Decon..
 [논문 요약] AlexNet
[논문 요약] AlexNet
1. Paper Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Communications of the ACM 60.6 (2017): 84-90. 2. Introduction AlexNet은 ILSVRC-2012 contest에서 기존의 머신러닝 기반 모델들을 모두 제치고, 1등을 차지한 최초의 딥러닝 모델입니다. 또한, 전년 우승작의 Top-5 error rate를 10%이상 감소시켰습니다. 3. ImageNet Dataset 1 ) Resize AlexNet은 ImageNet 데이터셋을 이용하여 모델 학습을 진행하였습니다. 이 ..
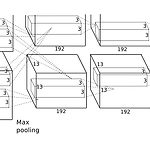
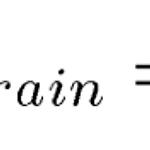 [논문 요약] LeNet
[논문 요약] LeNet
1. Paper LeCun, Yann, et al. "Gradient-based learning applied to document recognition." Proceedings of the IEEE 86.11 (1998): 2278-2324. 2. 전통적인 패턴 인식 1 ) feature extract를 위해서는 사전지식과 업무를 구체적으로 알아야합니다. 극단적인 예시로 모든 개는 수염이 없고 고양이는 수염이 있다고 가정한다면, 수염의 여부로 개와 고양이를 100퍼센트 분류해낼 수 있습니다. 이는 적절한 인식 시스템이 만들어졌다고 볼 수 있습니다. 이 예시는 개와 고양이를 분류하는 업무라는 것을 구체적으로 파악하는 것과 개와 고양이를 분류하는 특징은 수염이라는 것을 파악해야 올바른 인식 시스템을 만들 ..
 Batch Normalization
Batch Normalization
Paper Ioffe, Sergey, and Christian Szegedy. "Batch normalization: Accelerating deep network training by reducing internal covariate shift." International conference on machine learning. PMLR, 2015. Abstract 이전 레이어의 파라미터 값들 ( $ W, b $ )이 변하면, 현재 레이어 입력의 분포도 변한다. 이는 learning rate를 작게, weight initialization을 굉장히 예민하게 요구함으로써 학습속도를 늦춘다. 심지어, activation value가 saturation region으로 빠지게 만들 위험도 커진다. 이 현상을..
 Kaiming He initialization
Kaiming He initialization
Paper He, Kaiming, et al. "Delving deep into rectifiers: Surpassing human-level performance on imagenet classification." Proceedings of the IEEE international conference on computer vision. 2015. Kaiming He initialization Xavier Initialization의 가정 중 하나는 activation function이 linear여야한다는 것이다. 이는 ReLU에서 성립되지 않는다. 따라서, Kaiming He는 이를 해결하기 위해서 ReLU activation function에 맞는 He iniitalization을 고안하였다. Ka..
 Xavier Initialization
Xavier Initialization
Paper Glorot, Xavier, and Yoshua Bengio. "Understanding the difficulty of training deep feedforward neural networks." Proceedings of the thirteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2010. Xavier Initialization 논문에서 나온 Random Initialization의 문제점은 다음 그림과 같다. 보이다시피, 학습이 시작되자마자 마지막 레이어가 0으로 수렴해버린다. 저자는 이 현상이 마지막 레이어의 bias 값이..
 Lecun Initialization
Lecun Initialization
Lecun Initialization Random Initialization은 극단적인 경우에 모든 가중치 값들이 1이 되거나 -1이 될 수 있다. 이것을 방지하면 되지 않을까라는 생각에서 나온 것이 Lecun Initialization이다. 즉, $Z_i = \Sigma {X_j W_j}$에서 $Z_i$의 범위를 -1에서 1로 만들어 줄 수 있다면 Saturation 영역에 빠지지 않기 때문에 Random initialization의 문제를 해결할 수 있을 것이라고 예상한 것이다. $Z_i = \Sigma {X_j W_j}$에서 $Z_i$의 범위를 -1에서 1로 만들기 위해서는 가중치를 i 레이어의 노드의 개수를 나눠주면 된다. 이 i 레이어의 노드의 개수를 $fan_{in}$라 한다. 이 말을 정리하..
 Random Initialization
Random Initialization
Random Initialization Zero Initialization은 Activation function을 ReLU, tanh로 설정하면 가중치 업데이트가 전혀 이루어지지 않는 것을 볼 수 있다. 또한, Sigmoid로 설정시 업데이트가 되긴하지만 그 값이 매우 미미하여 학습이 잘 안될뿐만 아니라, 마지막 레이어를 제외하면 모두 같은 값으로 가중치가 업데이트 되기때문에 노드를 여러개 두는 것에 대한 의미가 퇴색된다. (표현력의 제한) 이를 해결하기위해 어떻게 가중치 초기화를 시키는게 좋을까? 매우 간단한 방법은 가중치를 정규분포로 초기화하는 것이다. 이를 Random Initialization이라 한다. Random Initialization의 문제점 다음과 같은 딥러닝 모델이 있다고 가정하자. ..