
- 딥러닝
- LeNet 구현
- Weight initialization
- Optimizer
- overfeat
- deep learning
- Convolution 종류
- object detection
- image classification
- SPP-Net
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Today
- Total
목록deep learning (27)
I'm Lim
 [논문 구현] LeNet
[논문 구현] LeNet
1. LeNet 구현 위 그림을 참조하여 아래와 같이 코드 구현을 진행하였습니다. class LeNet(nn.Module): def __init__(self): super(LeNet, self).__init__() self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0) self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0) self.conv3 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5, stride=1, padding=0) self..
 [논문 정리] Fast R-CNN
[논문 정리] Fast R-CNN
Paper Girshick, R. (2015). Fast r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 1440-1448). Abstract Fast R-CNN 모델은 기존의 R-CNN, SPP-Net, Overfeat과 달리 Classification과 Regression을 동시에 학습을 진행합니다. 또한, SPP-Net과 유사하게 학습시 입력으로 한장의 이미지만을 사용합니다. 그 결과, VGG-16을 기준으로 R-CNN에 비해 학습시간이 9배 빨랐고, SPP-Net에 비해 3배 빨랐다고합니다. 성능적인 측면에서도 mAP를 66%를 기록하면서 R-CNN보다 좋은 성능을 보였습니다. R-CNN and S..
 [논문 정리] SPP-Net
[논문 정리] SPP-Net
Paper He, K., Zhang, X., Ren, S., & Sun, J. (2015). Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE transactions on pattern analysis and machine intelligence, 37(9), 1904-1916. Abstract 기존의 CNN 모델 ( e.g, VGGNet, GoogLeNet, etc ) 등은 224 크기의 고정된 이미지 사이즈를 입력으로 사용합니다. 논문에서는 이것이 성능 저하를 야기할 수 있다고 주장합니다. 이를 해결하기 위해, Spatila Pyramid Pooling 개념을 도입하여 위와 같은 제한을 없앴습니다. 그..
 [논문 정리] Overfeat
[논문 정리] Overfeat
Paper Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., & LeCun, Y. (2013). Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv preprint arXiv:1312.6229. Introduction Overfeat 논문은 classification 문제와 detection 문제를 하나의 공유된 네트워크를 통해 학습시킵니다. 개인적인 생각으로 이 논문의 가장 핵심은 feature map을 sliding window의 관점으로 해석했다는 점입니다. Classification 1. Feature extractor..
Introduction 딥러닝은 optimizer로 Gradient Descent 기반의 기법을 사용합니다. 그러나, Quasi-Newton Method라는 다른 대안도 있습니다. 이 글에서는 왜 Quasi-Newton Method가 아닌 Gradient Descent을 사용하는지에 대해 알아보려고 합니다. Gradient Descent Gradient Descent의 기본적인 공식은 아래와 같습니다. $\large {\theta = \theta - \eta \nabla_{\theta} J(\theta)}$ Gradient Descent은 극소점을 찾는 것이 그 목적입니다. 위 식을 보면 알 수 있듯이, $J(\theta)$ 즉, 기울기가 0이 되버리는 순간에는 더 이상 $\theta$가 변하지 않고, ..
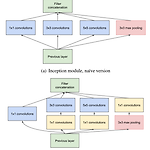 [논문 정리] GoogLeNet ( Inception v1 )
[논문 정리] GoogLeNet ( Inception v1 )
Paper Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. Abstract GoogLeNet은 ILSVRC 2014 우승을 차지한 모델로써 Inception 모듈을 통해 모델의 width를 늘림과 동시에 레이어의 depth를 22개까지 늘린 모델이다. Introduction GoogLeNet은 레이어를 22개를 쌓음으로써 ISLVRC 2012 우승 모델인 AlexNet의 성능을 제쳤다. 더욱 주목할만한 점은 AlexNet에 비해 12배나 적은 파라미터 수를 가진다는 것이다. Related Wor..
 [논문 정리] VGGNet
[논문 정리] VGGNet
Paper Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014). Introduction VGGNet은 ILSVRC 2014에서 2등을 한 모델이다 (참고로, 1위는 GoogLeNet이다). VGG는 우수한 성능에도 그 구조가 매우 간단하다는 장점이 있다. 본 논문에서는 kernel size에 집중하기 보다는 모델의 깊이에 (레이어의 개수) 더욱 집중했다. Model Configuration - VGGNet은 모든 Conv 레이어의 kernel size를 3 x 3으로 고정시켰다. - 각 Conv ..
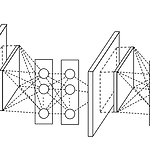 [논문 정리] Network In Network
[논문 정리] Network In Network
Paper Lin, Min, Qiang Chen, and Shuicheng Yan. "Network in network." arXiv preprint arXiv:1312.4400 (2013). Introduction 1. Generalized Linear Model Convolutional Neural Network는 Conv 레이어와 Pooling 레이어로 구성되어있다. CNN 필터는 feature map과 가중치 간의 선형 결합으로 표현된 후, non-linear function을 거친다. 이는 Generalized Linear Model (GLM) 과 유사한 방식이다. 따라서, 논문에서는 CNN 필터가 GLM 모델이라고 하였다. 2. Network In Network GLM은 latent space..