
- Convolution 종류
- SPP-Net
- object detection
- Weight initialization
- overfeat
- image classification
- deep learning
- Optimizer
- 딥러닝
- LeNet 구현
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Today
- Total
I'm Lim
Random Initialization 본문
Random Initialization
Zero Initialization은 Activation function을 ReLU, tanh로 설정하면 가중치 업데이트가 전혀 이루어지지 않는 것을 볼 수 있다. 또한, Sigmoid로 설정시 업데이트가 되긴하지만 그 값이 매우 미미하여 학습이 잘 안될뿐만 아니라, 마지막 레이어를 제외하면 모두 같은 값으로 가중치가 업데이트 되기때문에 노드를 여러개 두는 것에 대한 의미가 퇴색된다. (표현력의 제한)
이를 해결하기위해 어떻게 가중치 초기화를 시키는게 좋을까? 매우 간단한 방법은 가중치를 정규분포로 초기화하는 것이다. 이를 Random Initialization이라 한다.
Random Initialization의 문제점
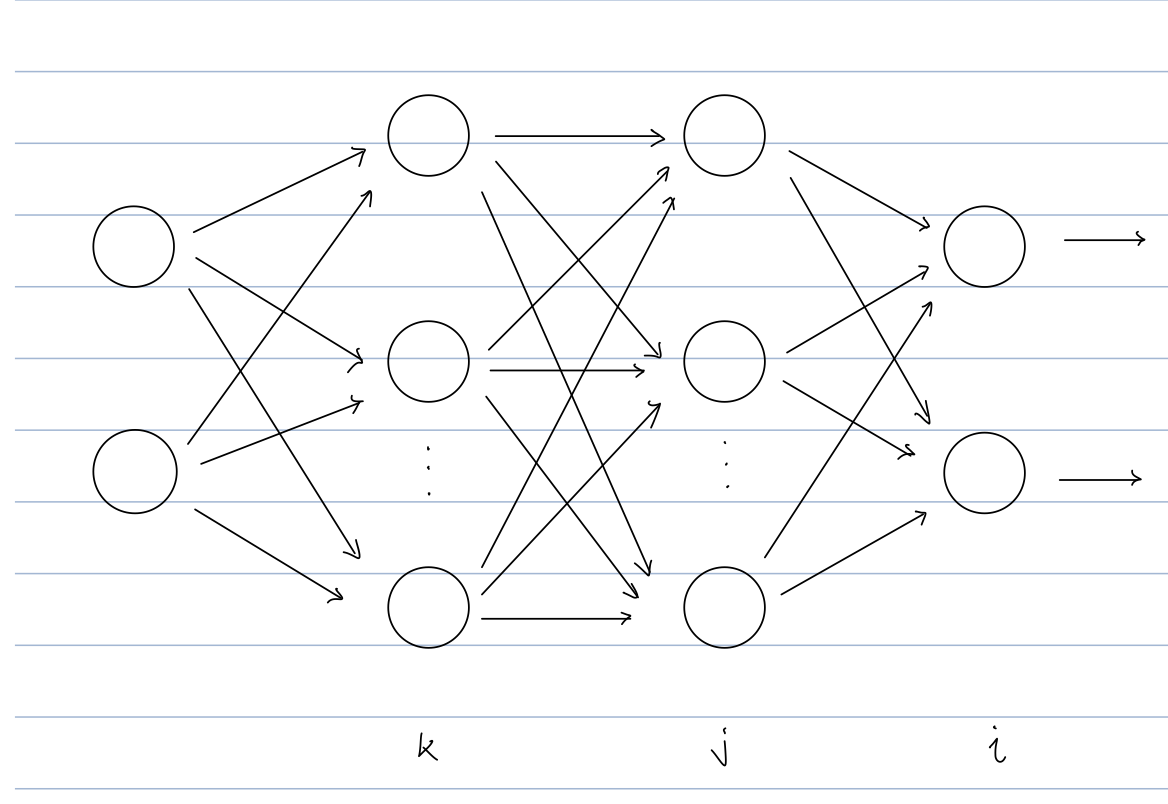
다음과 같은 딥러닝 모델이 있다고 가정하자. k 레이어의 노드가 100개라고 가정한다. 이 가중치들은 모두 정규분포 $X \sim N(0, 1)$에 의해 랜덤하게 결정된다. 말 그대로 랜덤하게 뽑히므로 극단적인 경우에는 각 가중치 값이 모두 1이 되거나 모두 -1이 될 가능성도 배제할 수 없다. 그렇게 된다면 입력 값 $X_k$가 모두 0.01이하 혹은 -0.01 이상이 아닌 경우 j 레이어로 넘어가는 activation value가 Saturation 영역 (= activation function의 기울기를 0으로 만드는 지점) 으로 빠지게 된다. 이렇게 되면 backpropagation value는 0이 되고, 가중치 업데이트가 안 된다.
Random Initialization의 의문점
위 문제점은 우선적으로 Activation function을 Sigmoid를 사용하였을 때이다. 그렇다면, tanh나 ReLU의 경우는 어떻게 될지에 대해 의문이 생겼다. tanh의 경우에는 non-saturation 영역이 sigmoid보다 좁으므로 더 많은 값들이 saturation 될 것이라고 예상한다. 또한, ReLU의 경우는 0보다 작으면 0을 내보내고, 0보다 크면 자기 자신의 값을 그대로 내보내기 때문에 0에 activation value들이 많이 모일 것으로 예상한다.
Random Initialization 실험
Random Initialization 실험을 위해서 간단한 딥러닝 모델을 생성하여 진행하였다.
- 모델 구조
- 첫 번째 레이어 : 100개의 node를 가진 Linear layer
- 두 번째 레이어 : 100개의 node를 가진 Linear layer
- 세 번째 레이어 : 100개의 node를 가진 Linear layer
- 네 번째 레이어 : 100개의 node를 가진 Linear layer
- 다섯 번째 레이어 : 100개의 node를 가진 Linear layer
- 입력 데이터
- 간단한 실험이므로 np.random.randn(1000, 100)을 이용해 정규분포에서 100개의 난수를 1000번 뽑았다.
1 ) $X \sim N(0, 1)$ ; 평균 = 0, 표준편차 = 1
- sigmoid
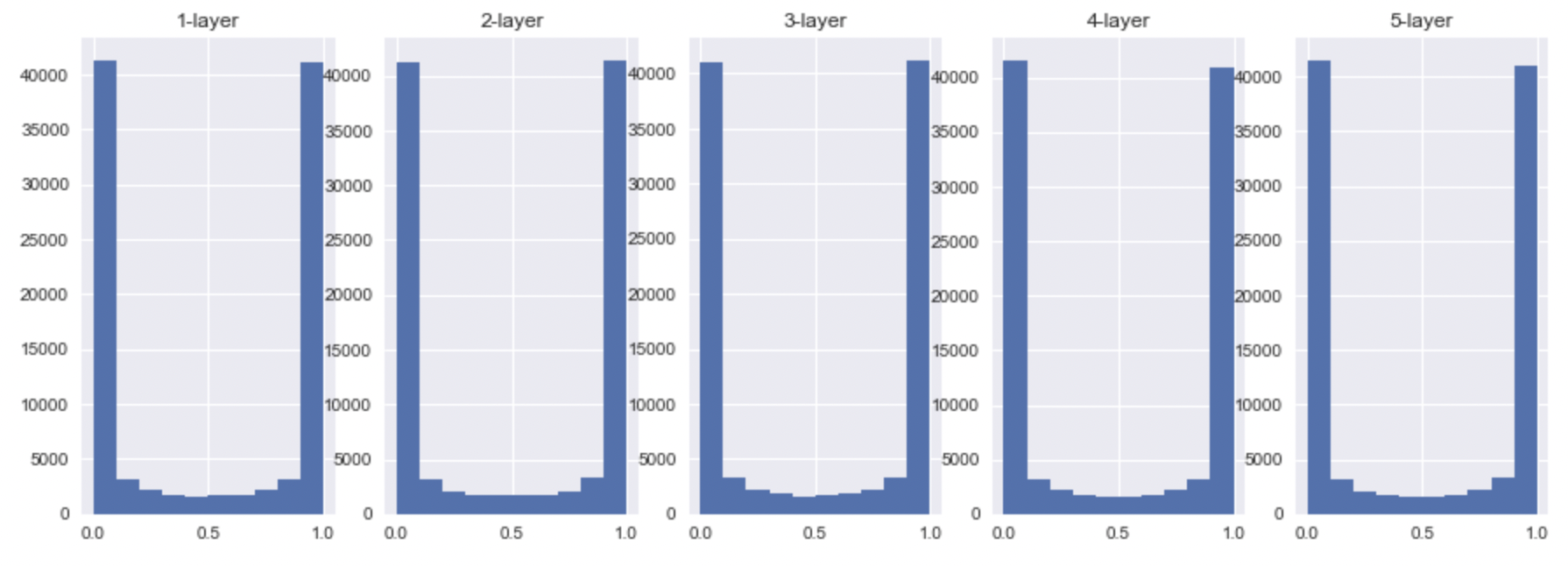
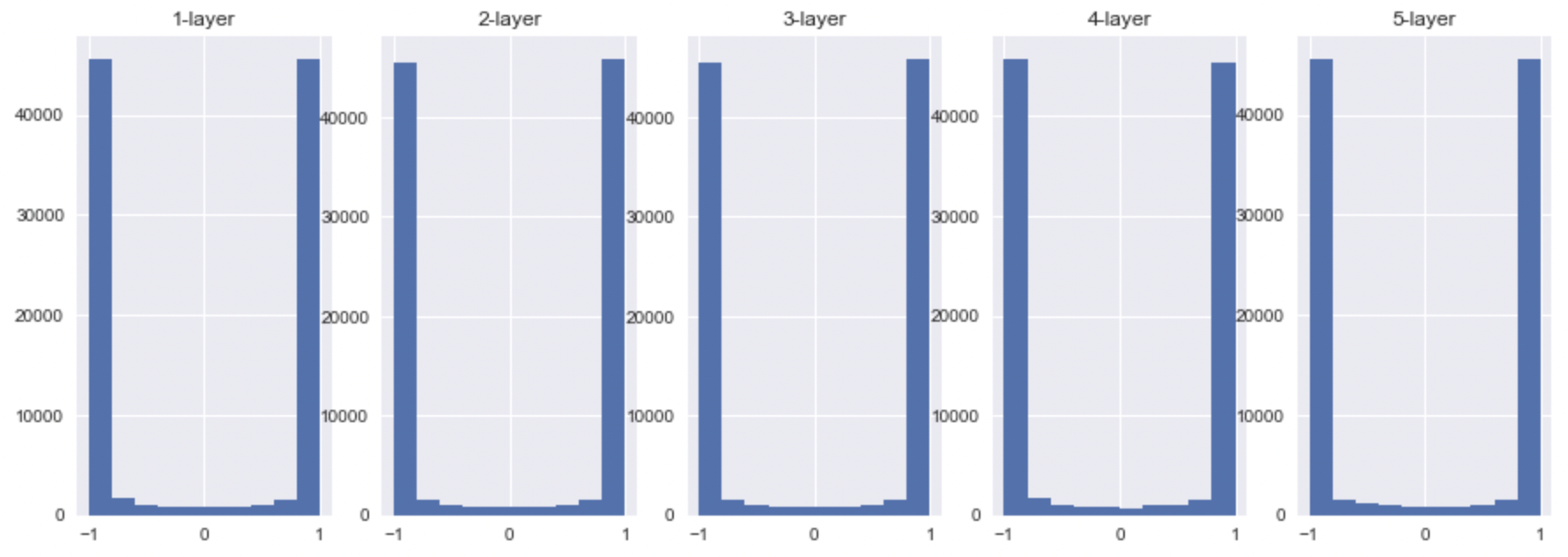
- tanh
- ReLU
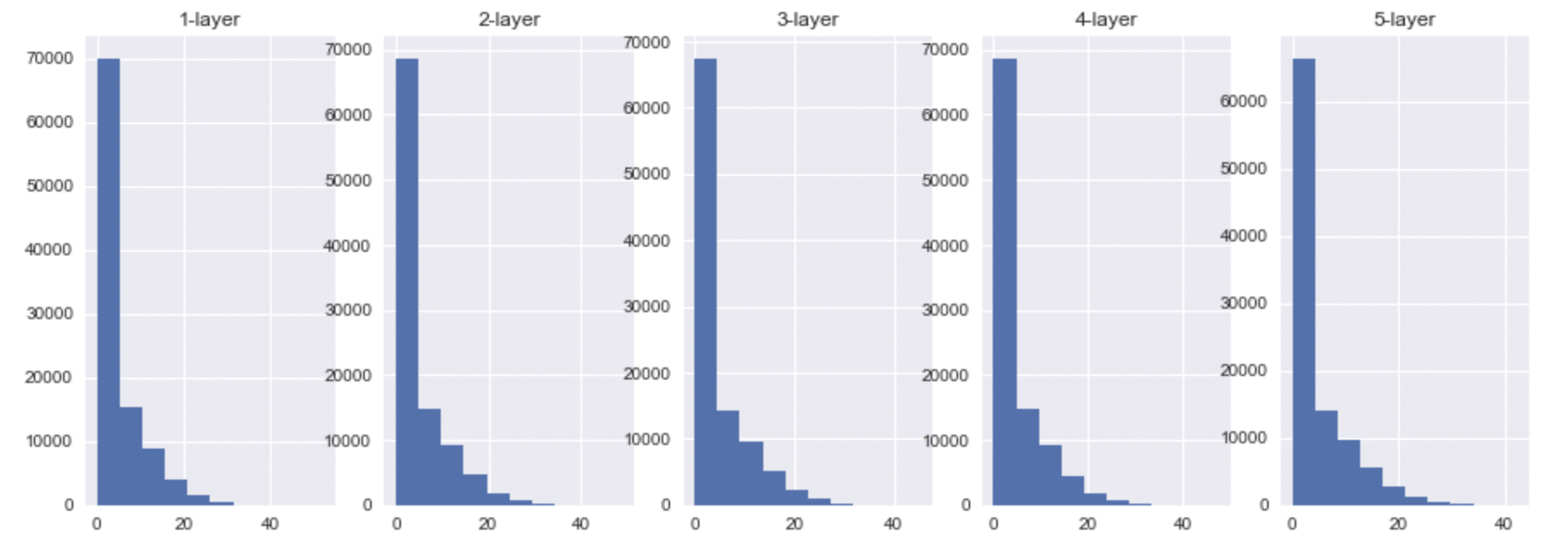
예상했듯이, tanh은 더 많은 값들이 saturation영역으로 빠진 것을 확인할 수 있었다. 또한, sigmoid는 activation value의 범위가 0~1인 것에 비해 tanh는 -1 ~ 1인것을 확인할 수 있었다. ReLU도 예상했듯이 saturation 영역인 0으로 많은 값들이 빠진 것을 확인할 수 있었고, 그 외의 값들은 굉장히 범위가 다양했음을 볼 수 있다. 이것은 또다른 문제를 발생시키는 데 이 출력 값들이 ( 또 다른 레이어의 입력값 ) 결국 backpropagation value에 관여되기 때문이다.
2 ) $X \sim N(0, 0.01^2)$ ; 평균 = 0, 표준편차 = 0.01
그렇다면 이 문제를 해결하기 위해서 표준편차를 줄이면 되지 않을까라는 의문이 생길 수 있다. 하지만, 이는 올바르지 못한 방식이다. 왜냐하면 결국 표준편차를 줄인다는 것은 zero initialization화 시킨다는 것이고, 이는 모든 가중치 값들을 0으로 수렴하게 만들 것이다. 다시말해, sigmoid의 activation value는 0.5로 모이게 될 것이고, tanh, ReLU의 경우에는 0으로 만들겠다는 말과 동일해지기 때문이다.
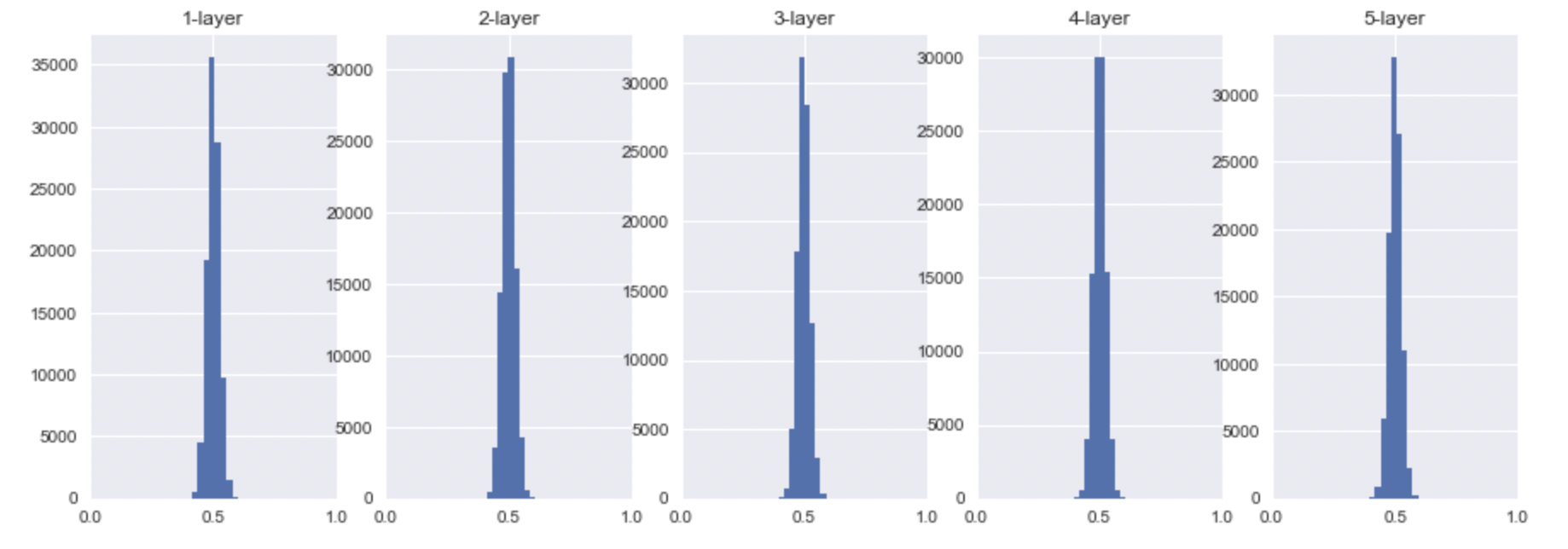
- sigmoid
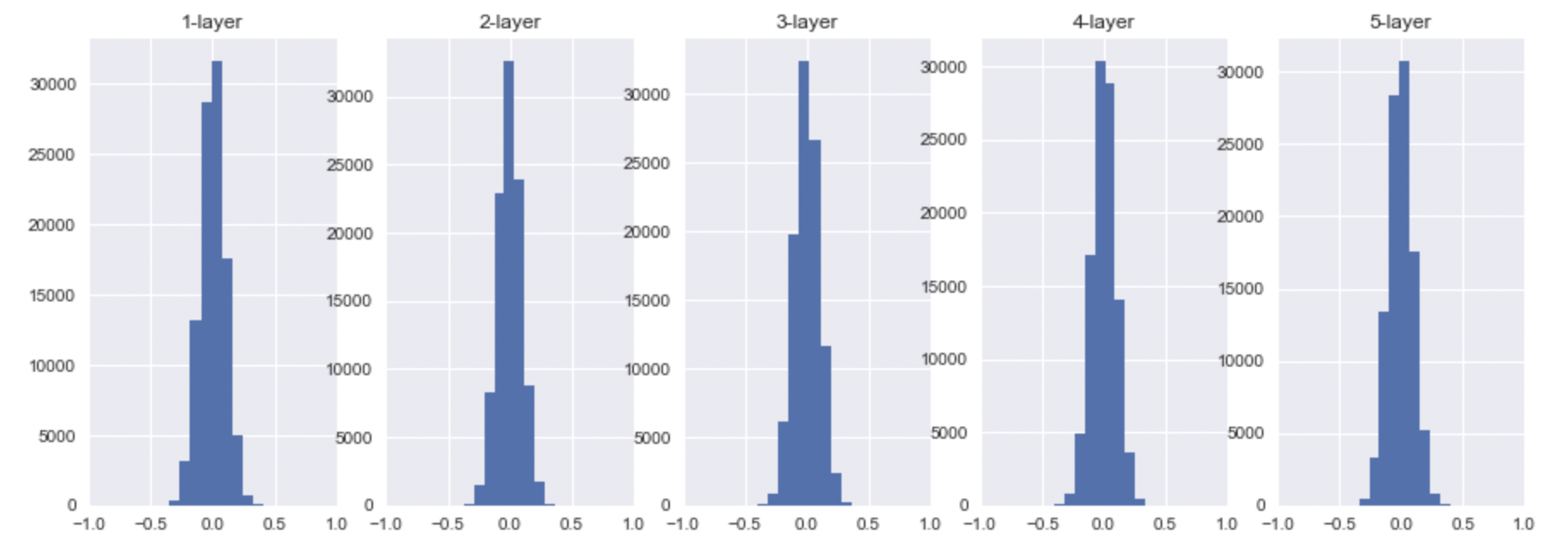
- tanh
- ReLU
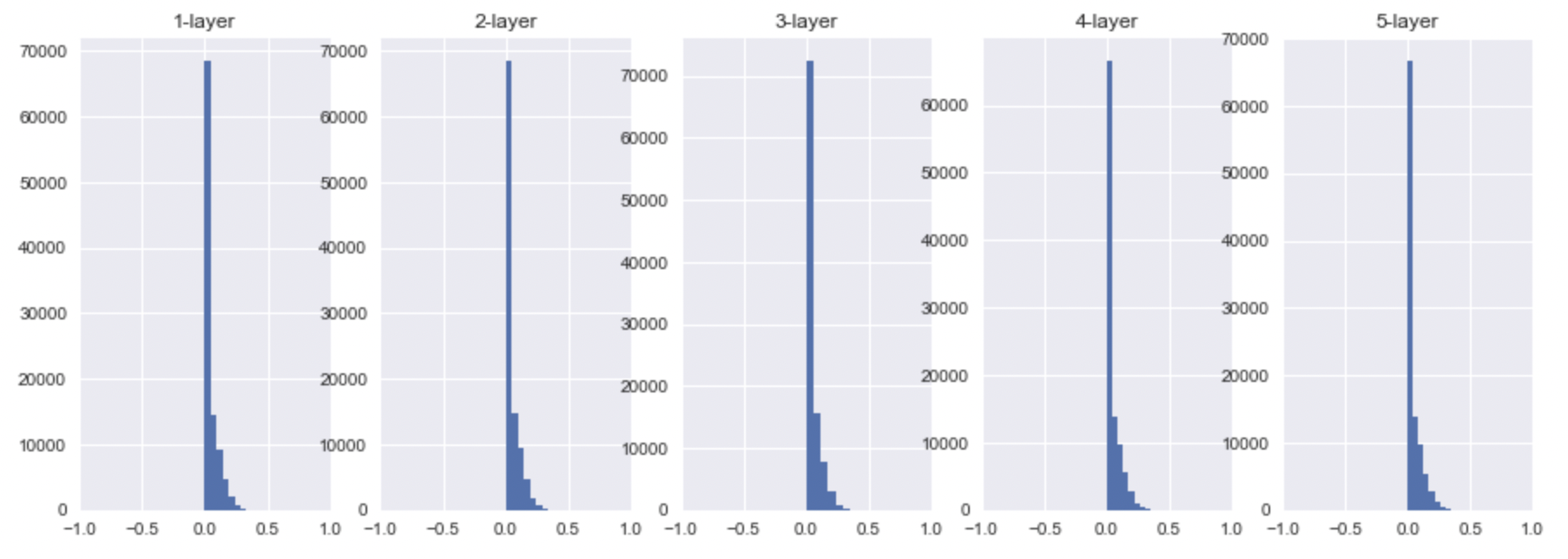
위에서 말했듯이, sigmoid의 activation value는 0.5로 모이게 될 것이고, tanh, ReLU의 경우에는 0으로 모이는 것을 확인할 수 있다.
'Deep Learning > Weight Initialization' 카테고리의 다른 글
| Kaiming He initialization (0) | 2022.10.29 |
|---|---|
| Xavier Initialization (0) | 2022.10.23 |
| Lecun Initialization (0) | 2022.10.23 |
| Zero Initialization (0) | 2022.10.23 |
| Weight Initialization (1) | 2022.09.30 |


