
- Weight initialization
- deep learning
- image classification
- Convolution 종류
- object detection
- LeNet 구현
- Optimizer
- overfeat
- SPP-Net
- 딥러닝
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Today
- Total
목록Classification (26)
I'm Lim
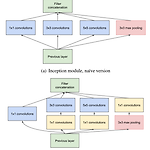
 [논문 정리] Inception v4
[논문 정리] Inception v4
Paper Szegedy, Christian, et al. "Inception-v4, inception-resnet and the impact of residual connections on learning." Thirty-first AAAI conference on artificial intelligence. 2017. Abstract 본 논문은 GoogLeNet의 Inception 모듈과 ResNet의 residual 모듈을 결합하여 Inception 모듈을 개선시킨 Inception v4에 대해 설명한다. Residual Inception Blocks 1. Stem module 위 모듈 구조를 Stem이라고 한다. Stem은 이미지를 직접적으로 입력으로 받는 모듈이다. 1 ) 초반부 3 x 3 Co..
 [논문 정리] Pre activation ResNet
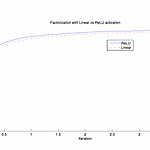
[논문 정리] Pre activation ResNet
Paper He, Kaiming, et al. "Identity Mappings in Deep Residual Networks." arXiv preprint arXiv:1603.05027 (2016) Abstract 본 논문에서는 Residual Block의 연산과정에 대해 분석하고, 이를 통해 새로운 Residual Block을 고안한다. Introduction 기존 ResNet 논문에서는 Fig. 1 (a)의 residual block을 사용했다. 이를 수식으로 풀면 다음과 같다. 여기서, h(xl)는 identity mapping을 의미하며, F(xl,Wl)은 residual mapping을 의미한다. 또한, f(yl)은 ReLU activation을 적용시킨다는 의미다. 저자의..
 [논문 정리] ResNet
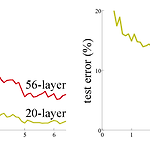
[논문 정리] ResNet
Paper He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. Abstract ResNet은 ILSVRC 2015 대회에서 우승한 모델로써 residual block이라는 이름의 모듈을 깊게 쌓은 모델이다. ResNet은 152개의 레이어 개수를 가진다. 이는 VGGNet보다 8배나 많은 레이어 개수고, 그럼에도 불구하고 ResNet은 lower complexity (파라미터 수가 적음)를 가진다. Introduction 1. degradation problem 기존의 모델들은 레이어를..
 [논문 정리] Inception v2, v3
[논문 정리] Inception v2, v3
Paper Szegedy, Christian, et al. "Rethinking the inception architecture for computer vision." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. Abstract AlexNet에서부터 GoogLeNet에 이르기까지 딥러닝 모델링의 방향성은 모델의 크기와 컴퓨터 계산비용을 늘림으로써 성능을 향상시키는 것이었다. 하지만, 계산비용과 파라미터 개수를 줄이는 것은 모바일 환경에서의 사용과 빅데이터 상황에서 유용하게 작용할 것이다. 본 논문에서는 위를 근거로 컴퓨터 계산 비용을 줄이는 연구를 진행할 뿐만 아니라 Regularization을 적..
 [논문 정리] GoogLeNet ( Inception v1 )
[논문 정리] GoogLeNet ( Inception v1 )
Paper Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. Abstract GoogLeNet은 ILSVRC 2014 우승을 차지한 모델로써 Inception 모듈을 통해 모델의 width를 늘림과 동시에 레이어의 depth를 22개까지 늘린 모델이다. Introduction GoogLeNet은 레이어를 22개를 쌓음으로써 ISLVRC 2012 우승 모델인 AlexNet의 성능을 제쳤다. 더욱 주목할만한 점은 AlexNet에 비해 12배나 적은 파라미터 수를 가진다는 것이다. Related Wor..
 [논문 정리] VGGNet
[논문 정리] VGGNet
Paper Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014). Introduction VGGNet은 ILSVRC 2014에서 2등을 한 모델이다 (참고로, 1위는 GoogLeNet이다). VGG는 우수한 성능에도 그 구조가 매우 간단하다는 장점이 있다. 본 논문에서는 kernel size에 집중하기 보다는 모델의 깊이에 (레이어의 개수) 더욱 집중했다. Model Configuration - VGGNet은 모든 Conv 레이어의 kernel size를 3 x 3으로 고정시켰다. - 각 Conv ..
 [논문 정리] Network In Network
[논문 정리] Network In Network
Paper Lin, Min, Qiang Chen, and Shuicheng Yan. "Network in network." arXiv preprint arXiv:1312.4400 (2013). Introduction 1. Generalized Linear Model Convolutional Neural Network는 Conv 레이어와 Pooling 레이어로 구성되어있다. CNN 필터는 feature map과 가중치 간의 선형 결합으로 표현된 후, non-linear function을 거친다. 이는 Generalized Linear Model (GLM) 과 유사한 방식이다. 따라서, 논문에서는 CNN 필터가 GLM 모델이라고 하였다. 2. Network In Network GLM은 latent space..
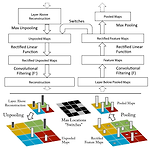 [논문 요약] ZFNet
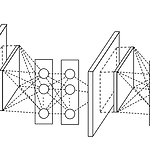
[논문 요약] ZFNet
1. Paper Zeiler, Matthew D., and Rob Fergus. "Visualizing and understanding convolutional networks." European conference on computer vision. Springer, Cham, 2014. 2. Introduction 이 논문은 ILSVRC 2012 우승을 차지한 AlexNet 모델을 분석합니다. AlexNet 모델의 성능이 굉장히 좋은 것은 사실이지만, 왜 그런지에 대한 설명은 없고, 그렇기 때문에 성능 개선시킬 수 있는지도 알 수 없습니다. 이 논문에서는 그 이유에 대해 분석하고, 모델을 개선시킴으로써 AlexNet보다 우수한 성능을 달성했습니다. 3. Visualization with a Decon..