
- image classification
- SPP-Net
- Convolution 종류
- deep learning
- Weight initialization
- LeNet 구현
- overfeat
- object detection
- Optimizer
- 딥러닝
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Today
- Total
I'm Lim
[논문 정리] VGGNet 본문
Paper
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014).
Introduction
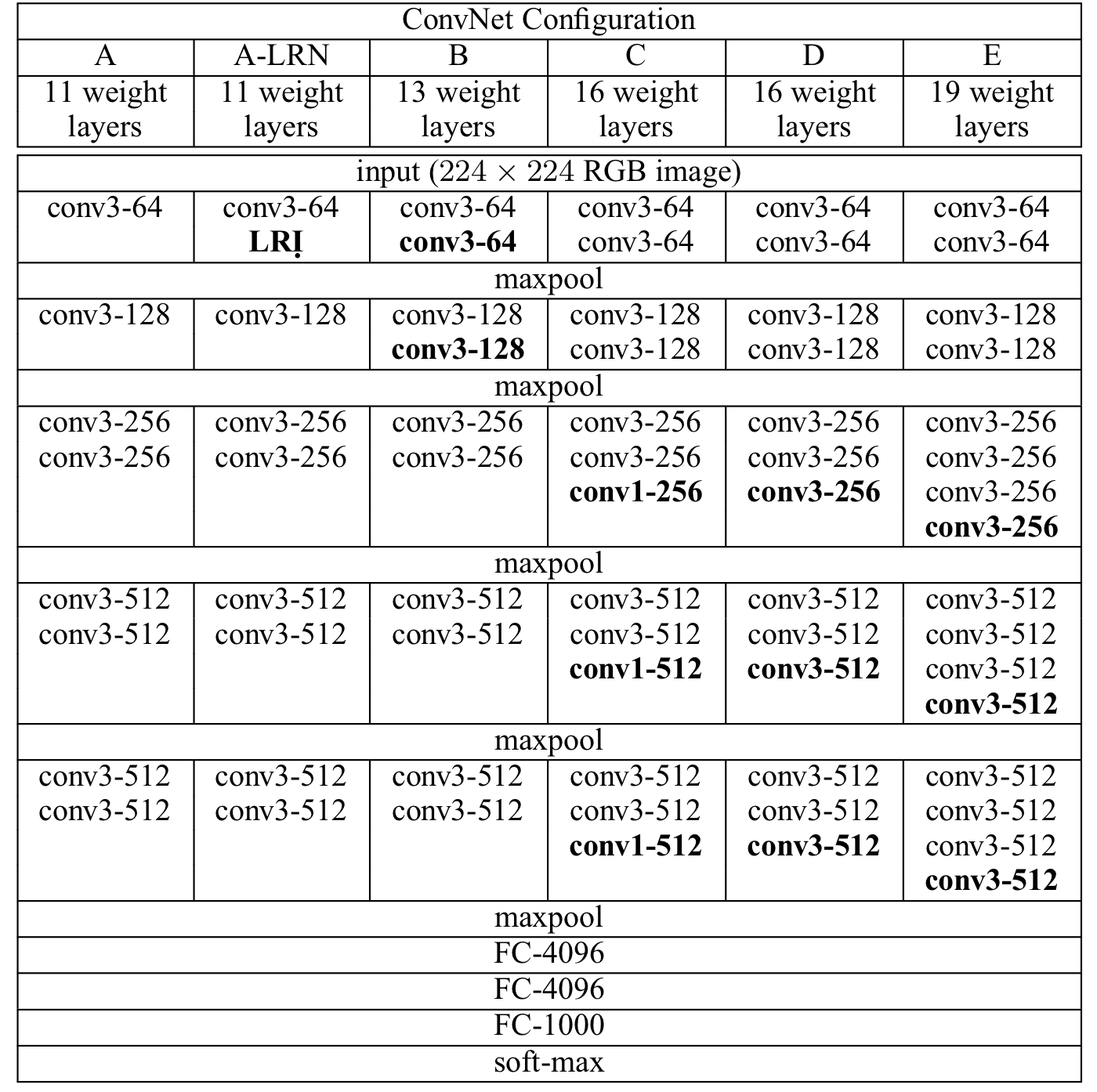
VGGNet은 ILSVRC 2014에서 2등을 한 모델이다 (참고로, 1위는 GoogLeNet이다). VGG는 우수한 성능에도 그 구조가 매우 간단하다는 장점이 있다. 본 논문에서는 kernel size에 집중하기 보다는 모델의 깊이에 (레이어의 개수) 더욱 집중했다.
Model Configuration
- VGGNet은 모든 Conv 레이어의 kernel size를 3 x 3으로 고정시켰다.
- 각 Conv 레이어의 stride는 1이고, padding 또한 1이다 (Conv 레이어에 의해 Spatial Resolution이 줄어들지 않게 하기 위해서).
- Spatial Resolution은 Max Pooling에 의해서만 줄어든다. Max Pooling은 kernel size : 2, stride : 2로 이루어져있다.
- 1 x 1 Conv 레이어를 사용한다 (Spatial Resolution을 유지하면서 비선형성을 증가시키기 위해).
AlexNet에서 나왔던 Local Response Normalization을 적용시킨 결과, 성능이 증가하지 않고 계산량만 늘려서 제거했다고 한다.
3 x 3 Kernel size
3 x 3 kernel size를 3번 적용시키는 것은 7 x 7 kernel size를 1번 적용시키는 것과 동일하다. 3 x 3 kernel size를 사용할 때의 장점에 대해 논문에서는 다음과 같이 설명한다.
- 3번의 ReLU를 적용시킴으로써 비선형성을 증가시킨다 (아마도, NIN에서 지적한 문제의 해결 방안으로 이야기 한 듯 하다).
- 계산량을 줄인다. 만약에, 3 x 3 filter를 3번 적용시키면 계산량이 3 x ( 3 x 3 ) x ( 입력 채널 개수 x 출력 채널 개수 ) = 27 x ( 입력 채널 개수 x 출력 채널 개수 ) 인데 7 x 7 을 한번 적용시키면 49 x ( 입력 채널 개수 x 출력 채널 개수 )의 계산량이 나온다.
Model Architecture
| VGG16-D | kernel_size | stride | padding | in_channel | out_channel | input_shape |
| Conv | 3 | 1 | 1 | 3 | 64 | (3, 224, 224) |
| Conv | 3 | 1 | 1 | 64 | 64 | (64, 224, 224) |
| MaxPool | 2 | 2 | (64, 224, 224) | |||
| Conv | 3 | 1 | 1 | 64 | 128 | (64, 112, 112) |
| Conv | 3 | 1 | 1 | 128 | 128 | (128, 112, 112) |
| MaxPool | 2 | 2 | (128, 112, 112) | |||
| Conv | 3 | 1 | 1 | 128 | 256 | (128, 56, 56) |
| Conv | 3 | 1 | 1 | 256 | 256 | (256, 56, 56) |
| Conv | 3 | 1 | 1 | 256 | 256 | (256, 56, 56) |
| MaxPool | 2 | 2 | (256, 56, 56) | |||
| Conv | 3 | 1 | 1 | 256 | 512 | (512, 28, 28) |
| Conv | 3 | 1 | 1 | 512 | 512 | (512, 28, 28) |
| Conv | 3 | 1 | 1 | 512 | 512 | (512, 28, 28) |
| MaxPool | 2 | 2 | (512, 28, 28) | |||
| Conv | 3 | 1 | 1 | 512 | 512 | (512, 14, 14) |
| Conv | 3 | 1 | 1 | 512 | 512 | (512, 14, 14) |
| Conv | 3 | 1 | 1 | 512 | 512 | (512, 14, 14) |
| MaxPool | 2 | 2 | (512, 14, 14) | |||
| Linear | 512 * 7 * 7 | 4096 | (512 * 7 * 7, ) | |||
| Linear | 4096 | 4096 | (4096, ) | |||
| Linear | 4096 | 1000 | (4096, ) |
VGGNet은 모든 Conv 레이어가 동일하게 kernel size : 3, stride : 1, padding : 1로 적용된다.
Max Pooling도 kernel size : 2, stride : 2로 동일하게 적용된다.
Details of Learning
- Training을 위해 본 논문에서는 momentum을 0.9로 두고, learning rate를 $10^{-2}$로 설정한 SGD를 사용하였다.
- Weight decay를 $5 * 10^{-4}$로 두었으며 batch size를 256로 두었다.
- Learning rate는 Early stopping 기법을 이용하여 validation accruacy가 증가하지 않는다면 10씩 나눠주었다.
- 처음 두개의 Linear 레이어에 dropout을 0.5로 설정하여 학습을 진행하였다.
- Weight initialization을 위해, 처음 4개의 Conv 레이어와 마지막 3개의 Linear 레이어를 VGGNet-A를 학습시켜 얻은 weight값으로 초기화시켰다. 나머지 Weight값들은 $W \sim N(0, 0.01)$로 설정하였다. 또한, Bias는 0으로 초기화 하였다 (이러한 pre-training 없이 Xavier Initialization으로 초기화 한 후, 학습을 진행하여도 학습이 잘 되었다고한다).
ImageNet Dataset
본 논문에서는 학습을 위해 ImageNet Dataset을 사용하였다. 전처리로는 AlexNet과 동일하게 RGB value의 평균값을 빼줬다.
Data Augmentation
1. Random Horizontal Flip : 좌우반전을 무작위로 진행
2. Random RGB color shift : AlexNet에서 진행한 것처럼 PCA를 진행 후, 얻은 값을 원래의 값에 무작위로 더해줌
3. 본 논문에서는 다양한 이미지 크기를 위해서 두가지 방식을 사용하였다.
1 ) Crop을 진행 전 rescale할 크기를 미리 정해 놓는 것이다 (이 rescale된 이미지 크기를 S라 한다). 논문에서는 S = 256과 S = 384를 사용하였다. 학습을 위해서는 S = 256 모델은 Details of Learning에 나온 방식으로 학습시킨다. S = 384 모델은 학습된 S = 256 모델의 가중치를 가져와서 learning rate를 $10^{-3}$으로 두고 학습시킨다.
2 ) Crop 진행 전 rescale할 크기를 범위로 지정하는 것이다. 즉, [$S_{min}, S_{max}$] 사이에서 random하게 rescale을 진행한다. 논문에서는 $S_{min}$ : 256, $S_{max} : 512$ 로 설정한다. 이 모델을 학습시키기 위해 S : 384 모델의 weight값들을 이용하여 fine-tuning을 하였다.
Testing
1. 이미지의 크기를 Q로 고정시킨다 (단, 이 때 Q는 S와 동일할 필요없다).
2. 첫 번째 Linear 레이어를 7 x 7 Conv 레이어로 교체하고, 나머지 2개의 Linear 레이어를 1 x 1 conv 레이어로 교체한다.
3. 1) Crop 시키지 않은 이미지와 2) 이 이미지에 horizontal flip을 적용시킨 이미지 두장을 테스트에 사용한다. 그러나, 이렇게 되면 마지막 출력 feature map 크기가 1 x 1이 아닐 수 있다. 이를 해결하기 위해, Global Average Pooling을 적용시킨다.
4. 3에서 얻은 softmax를 거친 2개의 값을 평균내어 최종 결과를 얻는다 (top-1 error, top-5 error).
Classification Experiments
1. Single Scale Evaluation
쉽게 이야기해서, 테스트 시에 입력으로 들어 갈 이미지의 크기를 하나로 고정시킨 후 성능 평가를 진행한 것이다. 학습 시 rescale을 할 크기를 미리 정해놓은 경우에는 Q = S로 설정하였고, 범위로 지정해 놓은 경우에는 Q = 0.5 * ($S_{min} + S_{max})$로 설정하였다.

1 ) LRN은 성능개선에 도움이 되지 않았다. ( A vs A-LRN )
2 ) 레이어의 깊이가 깊을수록 성능이 올라갔다. ( A에서 E로 갈수록 성능증가 )
3 ) Scale jittering을 주는 것이 성능개선에 도움이 된다. ( 같은 그룹 내에서 [256; 512]가 성능이 가장 우수 )
2. Muti-Scale Evaluation
쉽게 이야기해서, 테스트 시에 입력으로 들어 갈 이미지의 크기를 여러개로 사용하여 성능 평가를 진행한 것이다. 학습 시 rescale을 할 크기를 미리 정해놓은 경우에는 Q = { S-32, S, S+32 }로 설정하였고, 범위로 지정해 놓은 경우에는 Q = {$S_{min}, 0.5 (S_{min} + S_{max}), S_{max}$}로 설정하였다.

테스트 시에도 scale jittering을 주는 것이 성능개선에 더욱 도움이 되었음을 볼 수 있다.
3. Comparison with the state of the art in ILSVRC

아쉽게도 앙상블 기법을 적용한 GoogLeNet에 성능은 약간 못미치나, 단일 모델은 GoogLeNet보다 뛰어난 성능을 보였다.
Discussion
이 논문은 매우 간단한 구조를 사용하여 Inception Module에 견줄만한 성능을 보였다는 것에 의미가 있고, 모델의 깊이가 깊어질수록 성능이 개선됨을 보임으로써 모델의 깊이가 성능에 중요한 영향을 미침을 보였다.
'Classification' 카테고리의 다른 글
| [논문 정리] Pre activation ResNet (0) | 2022.11.20 |
|---|---|
| [논문 정리] ResNet (0) | 2022.11.20 |
| [논문 정리] Inception v2, v3 (0) | 2022.11.20 |
| [논문 정리] GoogLeNet ( Inception v1 ) (1) | 2022.11.11 |
| [논문 정리] Network In Network (0) | 2022.11.07 |



