
- Weight initialization
- LeNet 구현
- deep learning
- overfeat
- image classification
- 딥러닝
- SPP-Net
- object detection
- Optimizer
- Convolution 종류
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Today
- Total
I'm Lim
[논문 정리] GoogLeNet ( Inception v1 ) 본문
Paper
Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
Abstract
GoogLeNet은 ILSVRC 2014 우승을 차지한 모델로써 Inception 모듈을 통해 모델의 width를 늘림과 동시에 레이어의 depth를 22개까지 늘린 모델이다.
Introduction
GoogLeNet은 레이어를 22개를 쌓음으로써 ISLVRC 2012 우승 모델인 AlexNet의 성능을 제쳤다. 더욱 주목할만한 점은 AlexNet에 비해 12배나 적은 파라미터 수를 가진다는 것이다.
Related Work
이 논문이 발표할 당시에 딥러닝 모델의 성능개선을 위한 트렌드는 적절한 overfitting 방지 기법을 사용함과 동시에 레이어의 수와 레이어의 크기를 증가시키는 것이었다. 이를 위해서, GoogLeNet은 Inception 모듈을 반복적으로 쌓음으로써 레이어의 개수를 22개까지 증가시켰다.
본 논문에서는 1 x 1 Convolution을 두가지 목적으로 사용한다 (1. ReLU를 적용 // 2. 계산량 감소를 위한 차원 축소).
Motivation and High Level Considerations
단순히 모델을 깊게 쌓는 것은 두가지의 문제를 발생시킨다.
1 ) Overffiting이 발생하기 쉽다.
2 ) Computational resources가 한정적이며 낭비되기 쉽다.
이러한 문제를 해결하기 위한 방안으로 fully connected가 아닌 sparse layer를 사용하면 된다. 그러나, 현실적으로 Sparse Layer를 구성하기란 매우 힘들기 때문에 이미 존재하는 fully connected layer들로 sparse structure를 근사화시키고자 하였고, 그 결과 Inception 모듈을 고안하였다고 한다.
Architectural Details
1. Inception 모듈
위에서 Inception 모듈은 sparse structure를 근사화하는 CNN 모듈을 만들기 위해 고안되었다고 했다. 저자들은 이 sparse structure가 초기 레이어에서는 local region에 집중할 것이라고 가정하였다. 이를 위해서 Inception 모듈에 1 x 1 kernel size를 가진 conv 레이어를 넣었다고 한다. 또한, 3 x 3 과 5 x 5 kernel size를 가진 conv 레이어를 넣었는데 딱히 이유는 없다고 한다. 또한, 기존의 CNN 모델에서 Pooling 연산이 중요한 역할을 했으므로 Incpetion 모듈에도 Pooling 연산을 넣으면 좋을 것이라고 생각하여 Pooling도 넣었다고 한다.

2. 레이어별 채널의 개수
Inception 모듈은 stack되는 방식으로 각 출력들은 다양할 수 밖에 없다고 한다. 즉, high level feature는 레이어가 깊어질수록 많이 나타날 것이고, low level feature는 감소할 것이다. 이를 근거로 레이어가 깊어질수록 3 x 3 과 5 x 5 convolution의 비율을 늘렸다 (여기서 비율이 늘어난다는 의미는 채널의 개수가 증가한다는 말과 동일하다).
3. Computational Resource
위에서 말한 것처럼 3 x 3이나 5 x 5 convolution 채널의 개수를 증가시키면 레이어가 깊어질수록 출력 채널의 개수를 계속 증가시키게 된다. 이는 Inception 모듈의 2번째 Motivation에 위배된다. 이를 해결하기 위해서 즉, 채널의 개수를 감소시키기 위해서 사용되는 것이 1 x 1 convolution이다.
4. featuremap 크기
GoogLeNet에서는 feature map을 줄이기 위해서 Max Pooling을 사용했다.
GoogLeNet
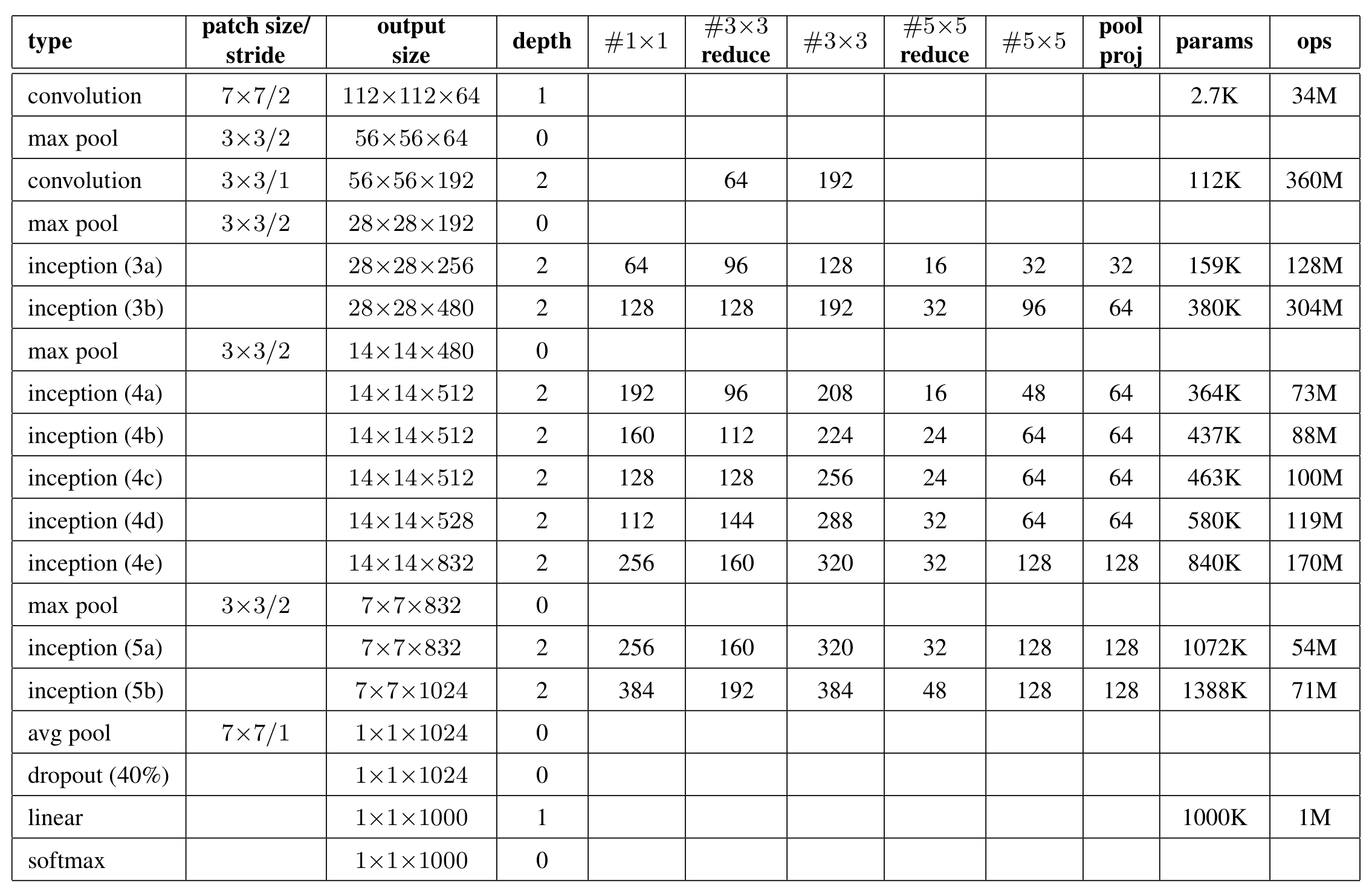
모든 Convolutional 레이어 뒤에는 ReLU를 적용했다고 한다. 아래 표에서 # 3 x 3 reduce는 3 x 3 Convolution전에 1 x 1 Convolution을 적용시켰다는 의미다. depth는 파라미터를 가진 레이어의 개수를 의미하고, depth 이후 params 이전까지의 값들은 채널의 개수를 의미한다. 따라서, GoogLeNet에서 파라미터를 가진 레이어의 개수는 총 22개다.
Auxiliary classifier
레이어가 깊어질수록 gradient vanishing problem이 발생하기 쉽고, 이를 방지하고자 레이어 중간중간에 Auxiliary classifier를 집어넣어줬다. 이 classifier는 loss 값을 구하고, 최종 loss에 0.3만큼 곱하여 더해진다. 테스트 시에는 auxiliary classifier를 뺀다. 이는 inception(4a)와 inception(4d)에 적용된다. Auxiliary Classifier의 세부사항은 생략한다.
Details of Learning
1. Training
- GoogLeNet 학습 시 Optimizer로 SGD를 사용하였고, momentum을 0.9로 설정하였다.
- 8 epoch마다 learning rate를 4%씩 감소시켰다. 이미지 샘플링 방식은 계속 바꾸었고, Dropout과 learning rate들을 계속 바꿔서 절대적인 기준을 제시할 수 없다고 한다.
- 그러나, 확실히 학습이 잘되는 샘플링 기법중 하나는 크기가 이미지 면적의 8%에서 100% 사이에 고르게 분포하고, 가로 세로 비율이 3/4에서 4/3 사이에서 무작위로 선택되는 이미지의 다양한 크기 패치를 crop하는 것이다.
2. 앙상블 기법을 이용한 성능개선을 위해 7가지 버전을 학습시켰는데 학습 시 차이는 샘플링 방식만 달랐다고 한다.
3. Test
- 이미지를 256, 288, 320, 352로 각각 rescale시킨다 ( 4 ).
- 왼쪽과 중앙 그리고 오른쪽 정사각형을 crop한다 ( 3 ).
- 224 크기로 각 모서리와 중앙 을 기준으로 crop한 이미지 그리고 224 x 224로 rescale한 이미지를 얻는다 ( 6 ).
- 좌우 반전까지 한 이미지를 모두 사용하였다 ( 2 ).
따라서, 테스트를 위해 이미지 당 4 x 3 x 6 x 2 = 144 crop을 사용하였다. 이후, softmax로부터 얻은 확률 값들을 단순 평균내서 성능을 평가했다.

Discussion
GoogLeNet은 1 ) 1 x 1 convolution을 Channel reduction을 위해 사용 2 ) Inception 모듈을 통하여 반복적으로 레이어를 쌓는 방식을 통하여 ILSVRC 2014에서 우승을 하였다. 어찌보면, NIN의 기조를 그대로 유지하면서 모듈의 width를 늘렸다고 할 수 있다.
'Classification' 카테고리의 다른 글
| [논문 정리] Pre activation ResNet (0) | 2022.11.20 |
|---|---|
| [논문 정리] ResNet (0) | 2022.11.20 |
| [논문 정리] Inception v2, v3 (0) | 2022.11.20 |
| [논문 정리] VGGNet (0) | 2022.11.10 |
| [논문 정리] Network In Network (0) | 2022.11.07 |



