
- SPP-Net
- deep learning
- image classification
- Optimizer
- Convolution 종류
- Weight initialization
- LeNet 구현
- 딥러닝
- overfeat
- object detection
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Today
- Total
I'm Lim
[논문 정리] PolyNet 본문
Paper
Zhang, Xingcheng, et al. "Polynet: A pursuit of structural diversity in very deep networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
Introduction
Image classification 모델은 지속적으로 모델의 depth나 width를 키우는 방향성을 띄었다. 그러나, 논문의 실험에 따르면 어느정도의 깊이보다 깊어지면 오히려 성능이 감소했고, width를 무한정 키우는 것에도 문제가 있다고 한다. 그러한 이유로 Inception 모듈의 조합으로 PolyInception 모듈을 고안하였다.

PolyInception and PolyNet
앞서 말했다시피, 모델의 성능을 올리기 위해서 가장 보편적인 방법은 레이어의 depth나 width를 키우는 것이다.
논문에서는 이것이 옳은 것인지 실험을 통하여 판단했다.
1 ) Depth

ResNet 269 모델까지는 depth를 키울수록 성능이 증가하였지만, 그 이후로는 성능이 크게 개선되지 않았다.
ResNet 269에서 ResNet 500으로 depth를 키울때, error rate는 0.1% 감소했는데, 파라미터의 수는 두배가 되었다고한다.
즉, 특정 depth보다 커지면 성능에 대한 depth의 영향이 줄어듦을 알 수 있다.
2 ) Width
만약, Width를 키우기 위해 모델 내 채널의 수를 모두 2배씩 증가시킨다고 하자. 그러면 Computational Complexity와 Memory 사용량이 4배가 증가하게 된다. 따라서, width를 무한정 키우는 것은 불가능하다.
위에서 살펴본 문제들 때문에 대안책이 필요했고, 논문에서는 그 대안으로 diversity에 집중하였다.
여기서 diversity란 모듈의 복잡도라 생각해도 무방하다.
1. PolyInception Module
diversity를 증가시키기 위해서 기본 모듈로 Residual Block을 사용하였다.
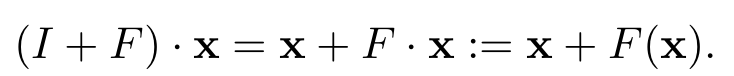
Residual Block을 수식으로 나타내면 위와 같이 나타나는데 $\textbf{x}$는 입력을, $I$는 identity mapping을, $F$는 residual mapping을 나타낸다. 여기서 $F$를 inception 모듈로 교체하면, 아래 그림과 같이 Inception residual unit이 된다.

논문에서는 diversity를 증가시키기 위해 아래와 같이 모듈을 변경하였고, 이를 PolyInception 모듈이라 명명하였다.

이 수식은 아래 그림의 (a)와 대응된다.

저자는 $F^2$가 모듈의 표현력을 증가시킨다고 주장한다.
(b)를 사용하면 (a)보다 computational cost가 2/3정도라고 한다. 또한, Inception F는 파라미터를 공유한다
( $F$와 $F^2$는 같은 $F$를 사용하기 때문에 위 그림에서 (a)와 (b)는 수식적으로 동일하다).
(c)를 보면 G라는 것을 볼 수 있다. 이것은 Inception G가 Inception F와 파라미터를 공유하지 않음을 뜻한다. 즉, Inception module G와 F의 파라미터가 따로 존재해야하므로 파라미터의 개수가 2배가 된다.
(d)를 보면 (b)나 (c)와 같이 Inception 모듈을 두번 거치는 2차 Incpetion 모듈이 아니라 1차 Inception 모듈임을 확인할 수 있다.
2. An Ablation Study
네트워크를 구성하기 이전에 PolyInception이 성능에 영향을 주는지에 관한 내용을 다룬다. 비교를 위해, Inception-ResNet v2를 사용하였다.

원래라면 Inception ResNet v2는 stage가 5-10-5로 구성되어 있지만, 이대로 진행하면 실험이 너무 오래 걸리므로 stage를 3-6-3으로 진행하였다고 한다. 그리고, 순서대로 stage A, stage B, stage C라고 하였다.
실험을 위해, 각 스테이지 (i.e, A, B, C)에 PolyInception 모듈 6개 (i.e., 2-way, 3-way, poly-2, poly-3, moly-2, m-poly3)를 각각 넣고 성능평가를 진행하였다. 따라서, 총 18개의 모델이 나온다.
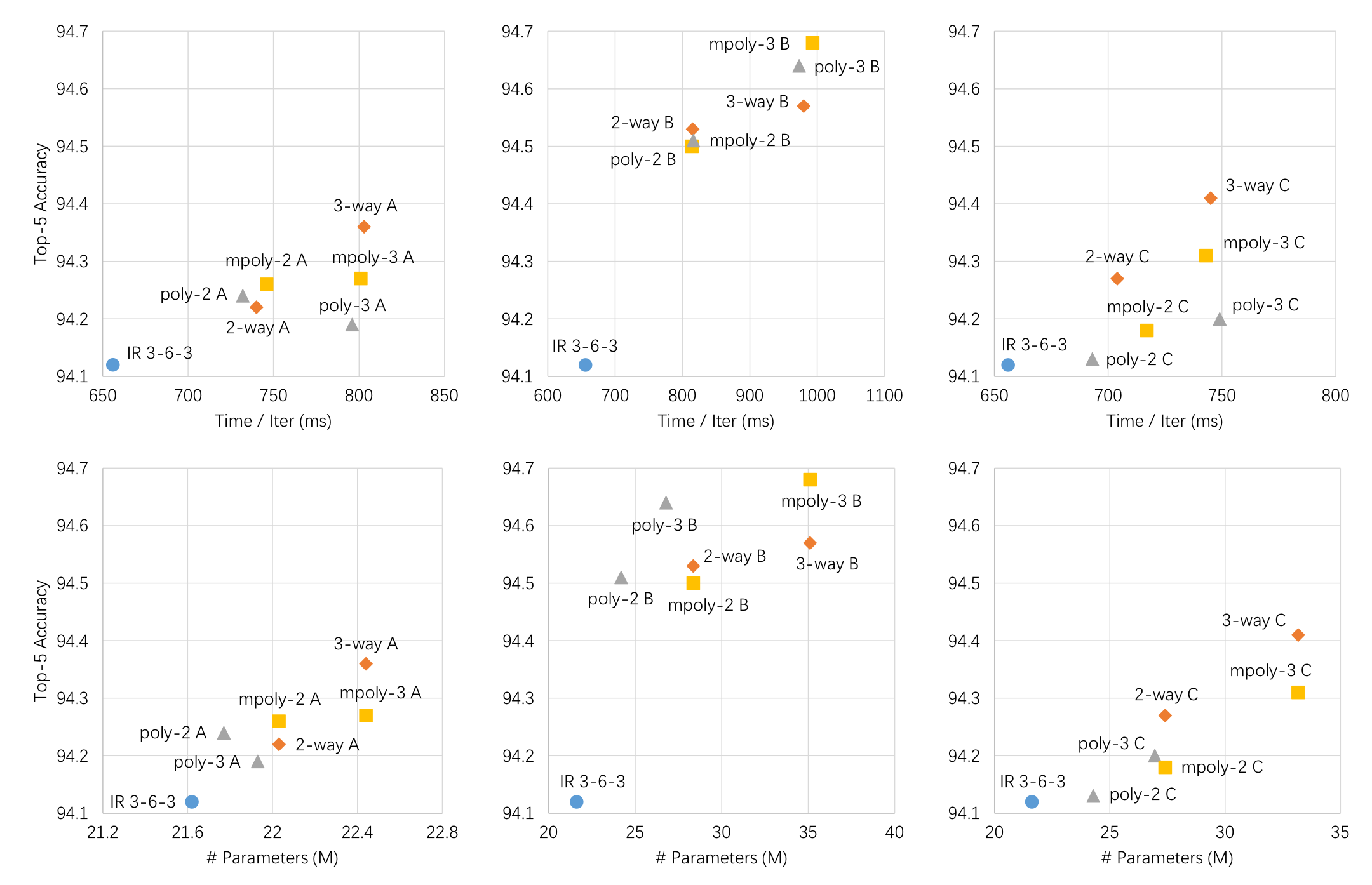
요약하자면, Inception ResNet v2의 stage A와 C를 PolyInception 모듈로 교체하는 것은 상대적으로 성능을 많이 높이진 못했다. stage B에서는 diversity가 증가함에 따라 성능도 개선되었다.
3. Mixing Different PolyInception Designs
위의 실험은 한 stage내 동일한 PolyInception 모듈을 사용한다. 논문에서는 만약 한 stage내에 여러 PolyInception 모듈을 섞어서 사용하면 성능에 어떠한 영향을 미치는지에 대한 실험을 진행하였다. 비교를 위해 Inception ResNet v2 6-12-6을 사용하였다. 또한, 위 실험의 결과로 stage B에만 집중하였다고 한다.


결과는 여러가지 PolyInception 모듈을 섞어 쓰는 모델의 성능이 가장 좋았다고 한다. 이는 diversity가 모듈 내에서만 존재하는 것이 아니라 모듈 간에도 존재하는 것을 보여준다.
4. Designing Very Deep PolyNet
위의 실험의 결과들로 모델을 구성하는데, 모델의 기본 틀은 Inception ResNet v2를 따랐다고 한다.
1 ) Stage A는 10개의 2-way PolyInception 모듈을 사용하였다.
2 ) Stage B는 poly-3와 2-way로 이루어진 Mixed PolyInception Module 10개를 사용하였다 (총 20개의 모듈).
3 ) Stage C는 poly-3와 2-way로 이루어진 Mixed PolyIncetion Module 5개를 사용하였다 (총 10개의 모듈).
Details of Learning
1. ImageNet Dataset
PolyNet 모델의 학습을 위해 ILSVRC의 training dataset을, 평가를 위해선 Validation dataset을 사용하였다.
2. Data augmentation
Augmentation을 위해서 Inception v1에서 사용한 기법인 Crop 비율을 전체이미지의 8%에서 100%로 하고, 각 이미지의 가로 세로 비율은 3/4 에서 4/3 사이로 하는 augmentation 기법을 사용하였다.
3. Training Settings
- 학습을 위해서 RMSProp을 사용하였고, weight deacy를 0.9, $\epsilon$ = 1.0을 사용하였다고 한다.
- Batch Normalization은 Inception v4에서 사용한 방식을 따랐다.
- Learning rate 초기값은 0.45였고, 160K iteration을 지날 때마다, 0.1을 곱하였다 (총 3번 감쇠하였다).
4. Weight Initialization
- Random Initialization은 학습을 느리게 하고, 잘 수렴하지 못하도록 하므로 아래 그림과 같이 이미 학습된 모델의 weight들을 끼워넣는 방식으로 가중치를 초기화하였다.

5. Residual scaling
Inception v4에서 언급한 것처럼 단순히 입력과 residual을 더하는 것은 불안정한 학습을 야기한다. 따라서, $\beta$를 곱하여 Residual scaling을 진행하고, 입력과 더해준다. 논문에서는 $\beta$ = 0.3으로 설정하였다고 한다.
$I + F + G$ -> $I + \beta F + \beta G$
6. Stochastic paths
레이어가 너무 깊어지면 Overfitting이 발생하기 쉬운데 이를 방지하기위해서 stochastic paths라는 것을 사용한다. Stochastic paths는 dropout과 개념이 유사한데 dropout은 노드의 연결을 확률적으로 끊는 반면, stochastic paths는 모듈의 path를 확률적으로 끊는다.

Overall Comparison

우선, 공정한 비교를 위하여 같은 computation budget의 모델들을 비교하였다고 한다. 그 결과, PolyNet이 ResNet보다 꾸준히 성능이 좋았고, 모델이 깊어질수록 Inception ResNet v2보다 성능 개선이 훨씬 잘 되었음을 보였다.
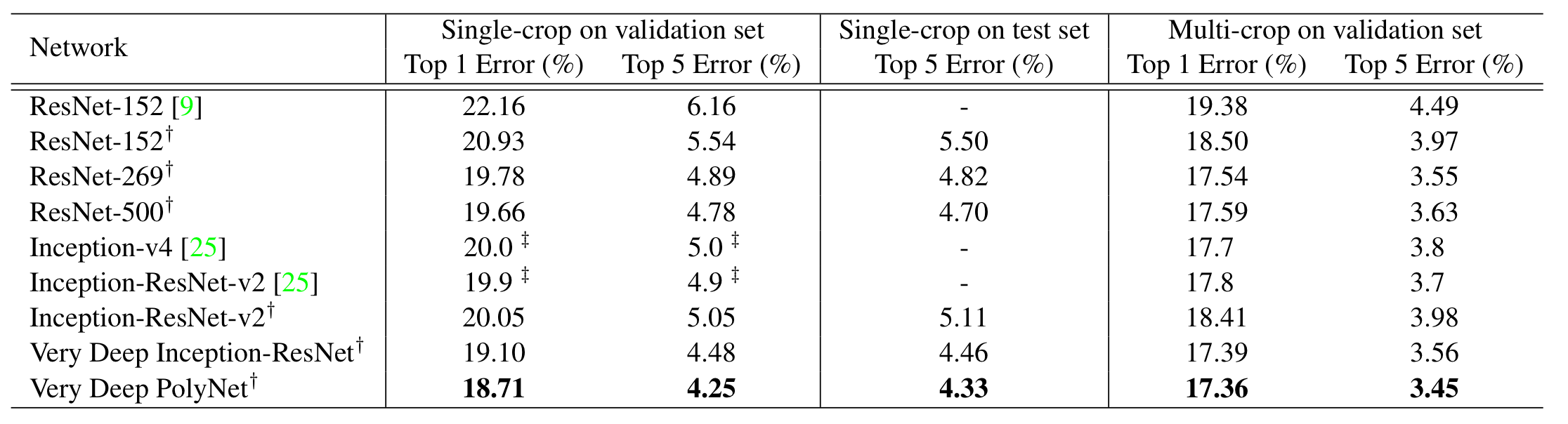
위의 결과 또한, PolyNet이 성능이 가장 좋았음을 보였다. 이러한 결과로, 저자는 diversity의 증가없이 단순히 depth만 증가시키는 것은 성능 개선에 큰 도움이 안될 것이라고 주장하였다.
Discussion
PolyNet은 기존의 Inception ResNet v2의 inception 모듈을 개선시키고, diversity라는 성능에 영향을 미치는 요소를 제안하였다. 또한, ablation study를 통하여 실험적으로 diversity가 depth나 width보다 성능 개선에 도움이 됨을 보였다.
'Classification' 카테고리의 다른 글
| [논문 정리] ShuffleNet v1 (0) | 2022.12.10 |
|---|---|
| [논문 정리] PyramidNet (0) | 2022.12.04 |
| [논문 정리] ResNext (0) | 2022.11.28 |
| [논문 정리] Xception (0) | 2022.11.27 |
| [논문 정리] SqueezeNet (0) | 2022.11.26 |



