
- deep learning
- image classification
- object detection
- Weight initialization
- Optimizer
- Convolution 종류
- 딥러닝
- SPP-Net
- overfeat
- LeNet 구현
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Today
- Total
I'm Lim
[논문 정리] SqueezeNet 본문
Paper
Iandola, Forrest N., et al. "SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size." arXiv preprint arXiv:1602.07360 (2016).
Abstract & Introduction
CNN 구조가 복잡해짐에 따라 모델이 요구하는 메모리가 증가하였다. CNN 모델의 크기를 줄이는 것은 세가지의 이점이 있다.
1 ) 분산 학습시 서버 간에 주고 받아야 할 데이터가 줄어든다.
2 ) 자율주행을 위해 클라우드에서 모델을 불러올 때, 작은 대역폭을 요구할 수 있다.
3 ) FPGA나 제한된 메모리를 요하는 하드웨어에 올릴 수 있다.
위 세가지의 이점을 실현시키기 위해서 고안된 것이 SqueezeNet이다.
SqueezeNet은 기존 모델과 같은 성능을 유지하면서 파라미터 수를 줄이는 것에 집중하였다. SqueezeNet은 ImageNet 데이터셋 정확도가 AlexNet 수준을 유지하지만, AlexNet보다 50배나 적은 파라미터 수를 가진다. 또한, Model Compression을 통해 SqueezeNet의 용량을 0.5MB이하로 줄일 수 있었다고 한다.
Related Work
1. Model Compression
Model Compression이란, 하드웨어적으로 딥러닝 모델의 경량화를 뜻한다. 이를 위해, Pruning, Quantization, Huffman Coding등이 사용된다 ( Han et al., 2015a ).
2. CNN micro-architecture
쉽게 말해, CNN micro architecture는 Inception module, Residual Block, Dense Block등과 같이 모듈화된 구조를 사용하는 CNN 모델을 뜻한다.
3. CNN macro-architecture
CNN macro architecture는 모듈들이 쌓여 이루는 모델 그자체를 뜻한다.
SqueezeNet
1. Architectural Design Strategies
1 ) 3 x 3 filter보다는 1 x 1 filter를 사용한다.
2 ) 3 x 3 filter전에 채널의 수를 줄인다.
3 ) large activation map을 위해 네트워크 후반부에 Down-Sample을 진행한다.
2. Fire module
GoogLeNet이 Inception module, ResNet이 Residual Block이라는 이름을 사용했듯이, SqueezeNet은 Fire module을 사용한다.

Fire module은 1 ) Squeeze 레이어, 2 ) Expand 레이어로 나뉜다.
1 ) Squeeze Layer는 채널의 수를 감소시키기 위해 사용된다.
2 ) Expand Layer는 feature map연산을 위해 사용된다.
Squeeze Layer의 출력 채널 개수는 Exapnd Layer의 출력 채널 개수보다 작게 설정한다.
3. SqueezeNet Architecture
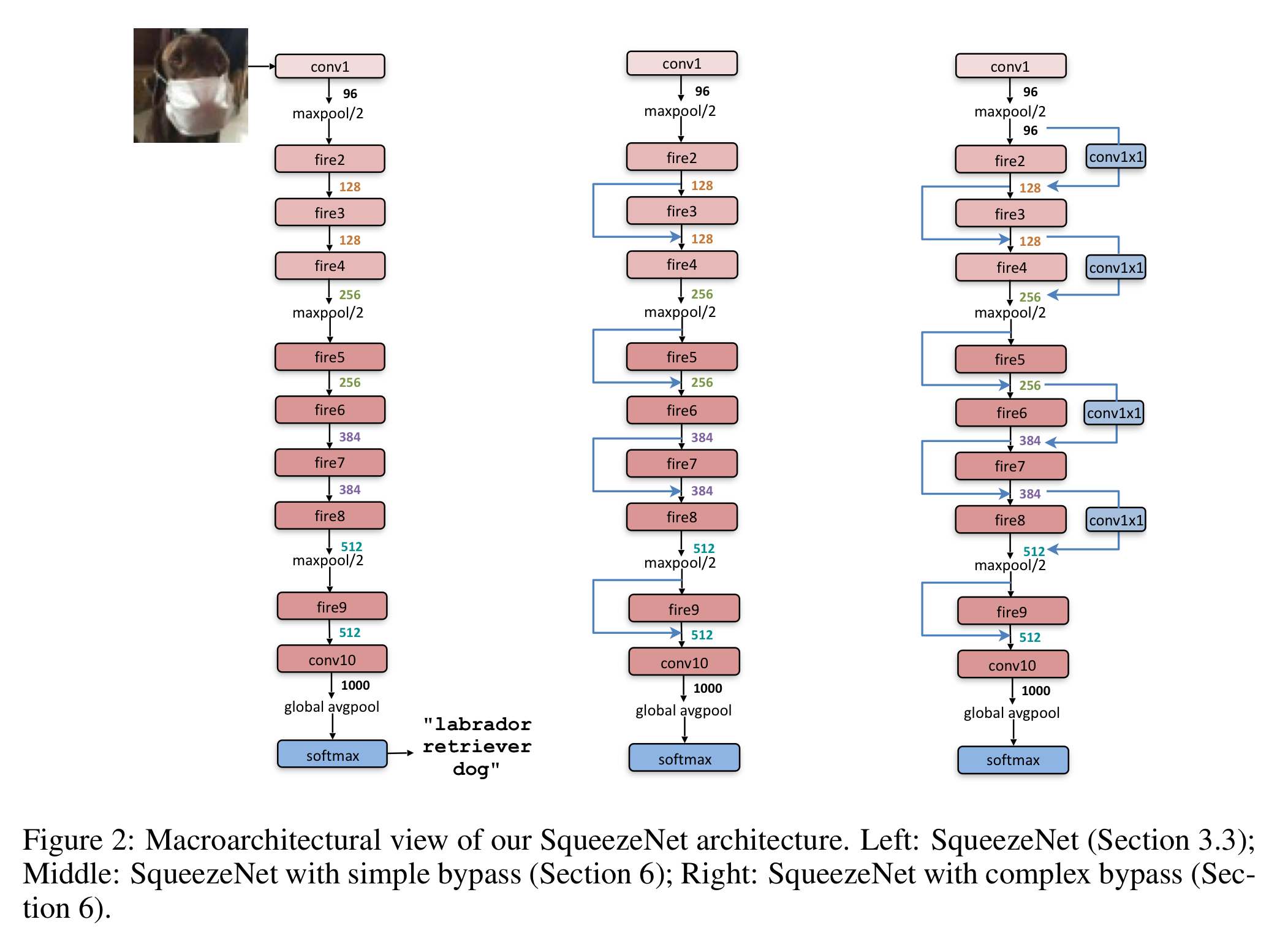
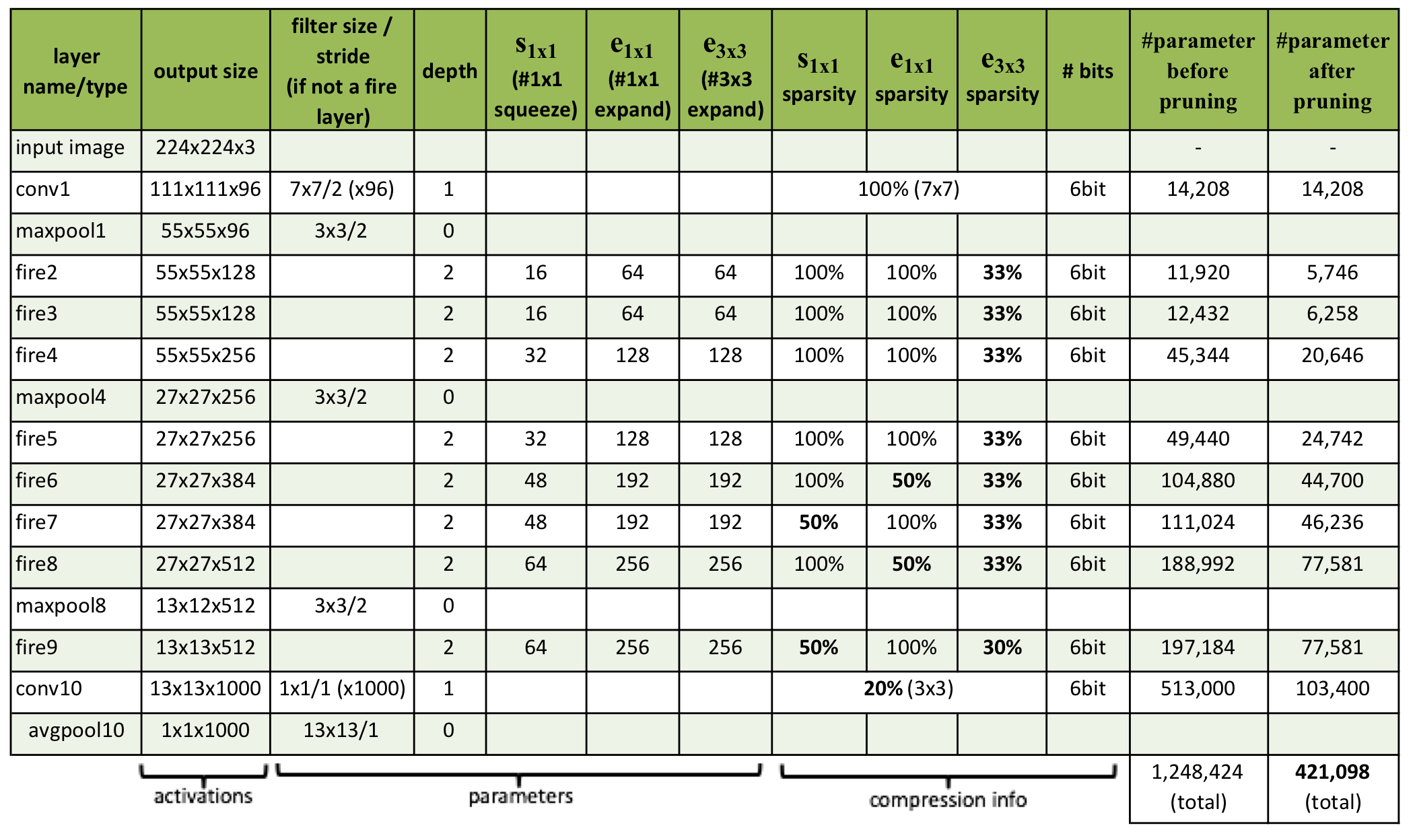
Evaluation of SqueezeNet
논문의 목표가 AlexNet을 압축시키는 것이기 때문에 비교 모델로 AlexNet을 사용했다고 한다.
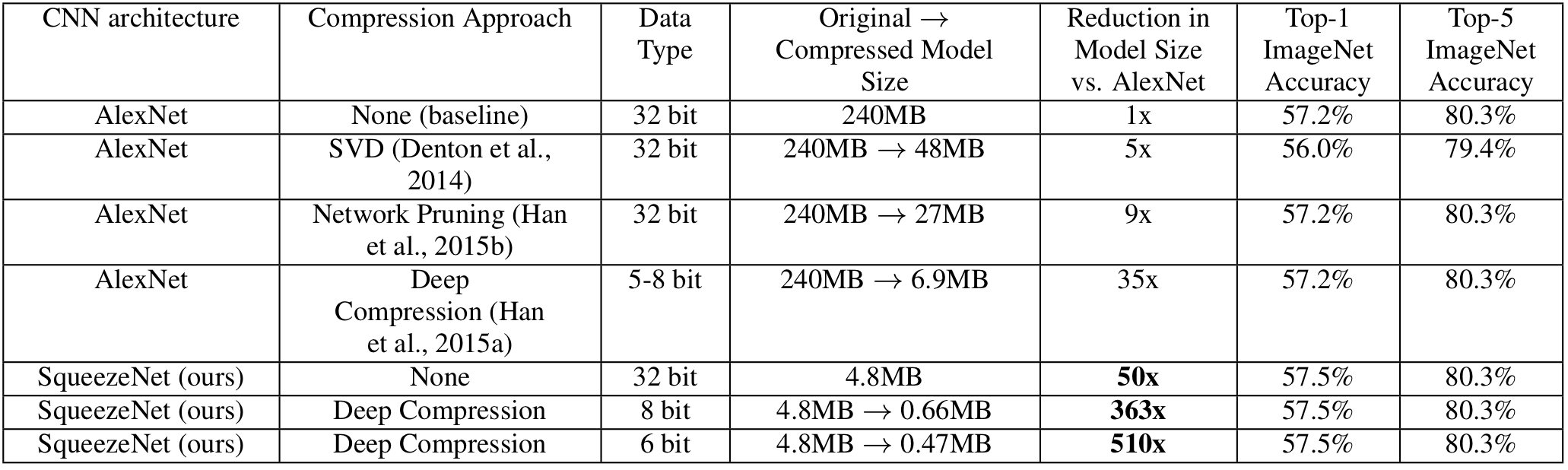
압축시키지 않은 SqueezeNet은 AlexNet에 비해 50배나 적은 파라미터를 가지면서 성능은 유지했다.
저자는 이렇게 작은 모델도 1 ) 압축이 가능한지 2 ) Quantization이 어디까지 가능한지에 대해 실험을 했다 ( 기본적으로 대표적인 딥러닝 프레임워크인 PyTorch, TensorFlow는 기본 Tensor 크기를 float32로 설정한다 ). 그 결과, SqueezeNet은 6 bit Quantization로 압축을 시켰을 때도 성능을 유지했다.
CNN micro-architecture design space exploration
논문에서는 여기서 더 나아가 최적의 Fire module을 찾기 위해 실험을 진행하였다.
1. CNN micro-architecture metaparameters
- $base_e$ : 첫 번째 fire module의 출력 채널 수
- $freq$ : fire module의 개수
- $incr_e$ : 출력 채널 수 - 입력 채널 수
- $e_i$ = $base_e$ + $( incr_e \: [ \dfrac {i}{freq} ] )$
- $e_i$ = $e_{i, 1x1} + e_{i, 3x3}$ // $pct_{3x3}$ : fire module 내 3 x 3 Conv의 비율
- $Squeeze Ratio \: (SR)$ : Expand Layer의 채널 개수 / Squeeze Layer의 채널 개수
SqueezeNet Architecture에서의 표는 $base_e$ = 128, $pct_{3x3}$ = 0.5, $incr_e$ = 128, $freq$ = 2, $SR$ = 0.125인 특별한 경우다.
2. Squeeze Ratio
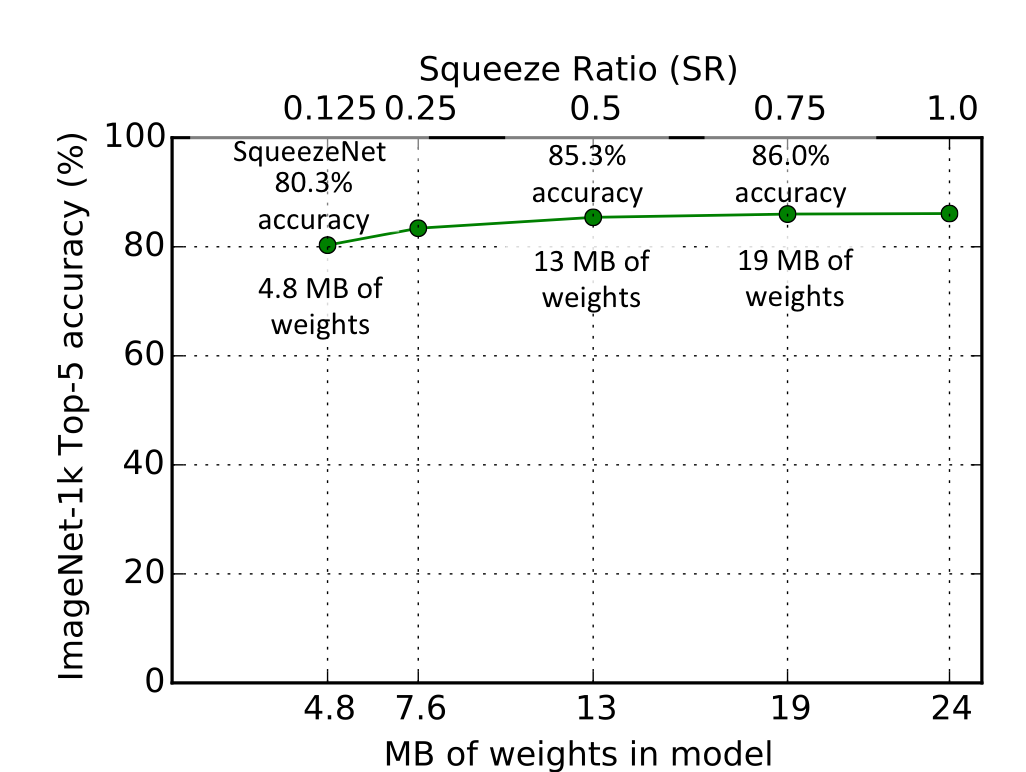
위 그림은 앞에서 설명했던 파라미터 중 SR을 바꾸면서 실험을 진행한 결과이다. 기준 모델은 SqueezeNet Architecture에서의 표에서 나온 모델이다.
보이다시피, SR이 0.75 이상이 되면 성능의 개선이 없다. 따라서, 모델 성능을 개선시키기 위해 SR = 0.75를 사용할 수 있을 것이다.
3. Trading off 1 x 1 and 3 x 3 filters
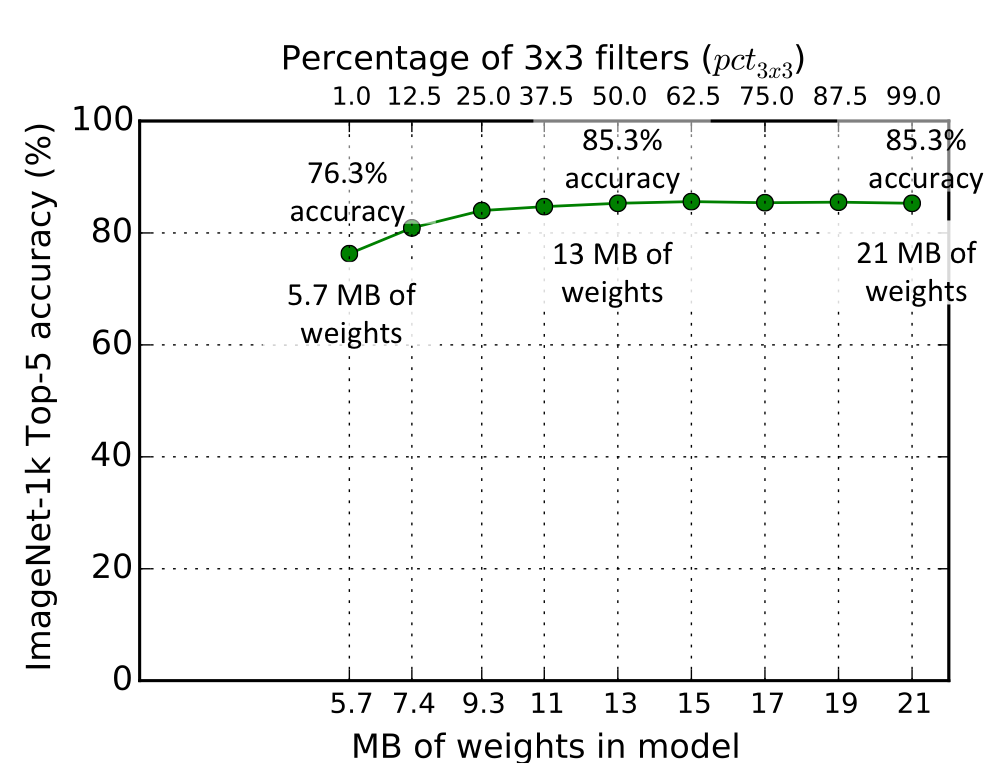
위 실험은 $pct_{3x3}$을 바꿔가며 실험을 진행한다. 즉, fire module 내 3 x 3 Conv의 비율을 1%에서 99%까지 바꿔가며 성능평가를 진행한다. 기준 모델로는 $base_e$ = $incr_e$ = 128, $freq$ = 2, $SR$ = 0.5로 설정한다.
위의 결과에서 보이다시피, $pct_{3x3}$이 0.5을 넘어가면 성능이 개선되지 않았다.
CNN macro-architecture design space exploration
이 실험은 모델의 전체적인 구조를 수정하면 ( shortcut connection을 추가하면 ) SqueezeNet의 성능이 개선되는지 알아보고자 진행하였다. 실험의 모델은 아래에 나와있으므로 생략한다.

물론 Complex Bypass도 성능은 개선시켰으나, skip connection만을 적용시킨 Simple Bypass 모델이 가장 성능을 크게 개선시켰다 ( skip connection의 연결 방식은 ResNet과 동일하다 ).
Discussion
SqueezeNet은 AlexNet과 동일한 성능을 유지하면서도 파라미터 수를 50배나 줄인 모델이다. 심지어, 압축된 SqueezeNet은 0.5MB보다 작은 용량을 가진다. 이는 FPGA에 올릴 수 있는 수준이다. 이러한 경량화된 모델을 통해 향후 임베디드 시스템에 효율적으로 딥러닝 모델을 사용할 수 있게 될 것이다.
'Classification' 카테고리의 다른 글
| [논문 정리] ResNext (0) | 2022.11.28 |
|---|---|
| [논문 정리] Xception (0) | 2022.11.27 |
| [논문 정리] DenseNet (0) | 2022.11.26 |
| [논문 정리] Inception v4 (0) | 2022.11.20 |
| [논문 정리] Pre activation ResNet (0) | 2022.11.20 |



