
- Optimizer
- image classification
- SPP-Net
- Convolution 종류
- Weight initialization
- LeNet 구현
- overfeat
- 딥러닝
- deep learning
- object detection
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Today
- Total
I'm Lim
[논문 정리] ResNext 본문
Paper
Xie, Saining, et al. "Aggregated residual transformations for deep neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
Abstract
ResNext는 기존의 모듈기반의 Image Classification 모델과 같이 모듈을 반복적으로 쌓는 구조를 갖는다. 그러나, ResNext는 기존의 모델에서 필수적인 요소로 여겨지던 "Width"와 "Depth"에 "Cardinality"라는 요소를 도입하였다. Cardinality를 증가시키는 것이 width나 depth를 증가시키는 것보다 성능 개선에 훨씬 효과적이라고 한다.
Introduction
Inception 모듈이 비록 성능이 좋긴 하지만 필터의 수, 커널 사이즈 등 고려사항이 너무 많다. 이것의 문제점은 새로운 데이터셋에 Inception 모듈을 학습시킬 때, 하이퍼 파라미터를 어떻게 설정해야될지 모른다는 점이다.
이를 방지하고자 논문에서는 아래와 같이 매우 간단한 모듈을 사용하였다.
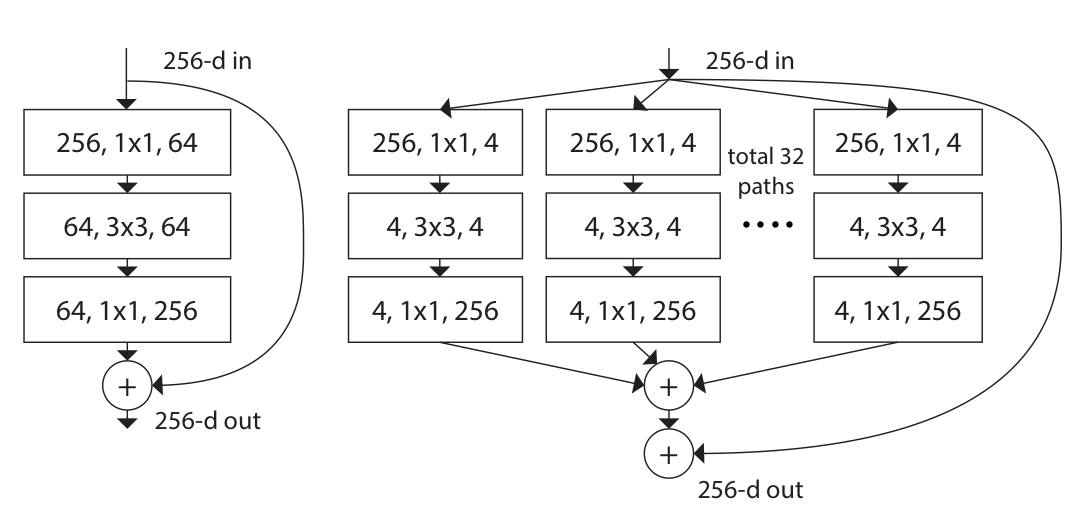
또한, 위 그림은 아래와 같이 표현할 수 있다.

위 그림 (c)에서 group의 개수가 cardinality다. 즉, ResNext 모듈 내 group의 개수를 cardinality라고 한다.
실험을 통해 cardinality를 증가시키는 것이 width나 depth를 늘리는 것보다 훨씬 더 성능 개선에 효과적이었다고 한다.
Method
1. Template

위 표는 ResNext-50의 모델 구조를 나타낸다. 앞서 말한 것과 같이 위 ResNext-50의 cardinality는 한 모듈 내 3 x 3 conv group의 개수다 (C=32).
2. Revisiting Simple Neurons
ResNext의 블록 내 연산과정은 Weighted sum 연산과정과 매우 흡사하다.
$\textbf{x} = [ x_1, x_2, ..., x_D]$이고, D채널 입력 벡터라고 하자. 그리고, $w_i$를 i번째 Conv 레이어라고 한다면 ResNext의 모듈 내 연산은 $\Sigma_{i=1}^D \: W_i \: x_i$라고 할 수 있다.
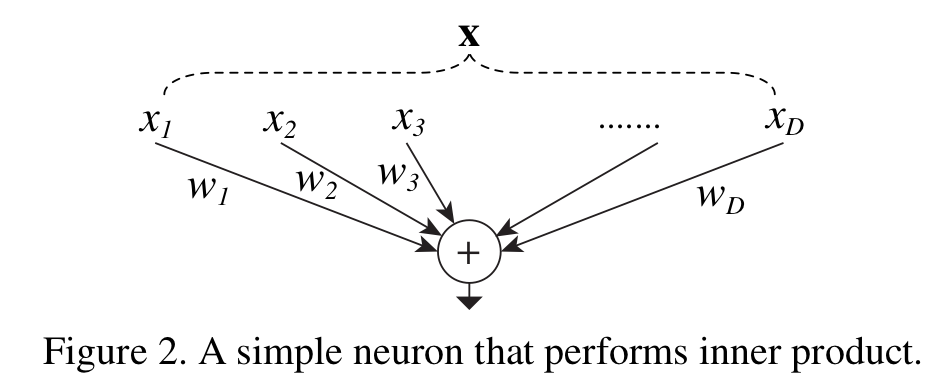
위 연산은 세가지로 나눠서 생각해볼 수 있다.
1 ) Splitting : $\textbf{x}$가 낮은 차원으로 임베딩 된다 (1 x 1 Conv 연산에 의해 채널의 개수를 줄인다).
2 ) Transforming : 낮은 차원의 벡터가 $w_i \: x_i$로 변환된다 (3 x 3 Conv 연산에 의해 feature map 연산을 진행한다).
3 ) Aggregating : 변환된 결과가 하나로 합쳐진다 (3 x 3 Conv 결과들을 concatenate한다).
3. Model Capacity
실험을 위해, 본 논문에서는 cardinality를 하이퍼 파라미터로 두고 실험을 진행한다. 비교모델은 width가 64인 ResNet-50 모델을 사용하였다. ResNext의 cardinality와 width는 ResNet-50 모델과의 비교를 위해 유사한 capacity (FLOP)를 가지도록 아래와 같이 설정하였다.

여기서, width of bottleneck d는 1 x 1 Conv 레이어의 출력 채널 개수를 뜻하고, width of group conv는 3 x 3 conv 레이어의 출력 채널 개수를 뜻한다.
Experiments on ImageNet-1K
1. Cardinality vs Width


본 실험은 고정된 complexity를 갖는 모델에서 cardinality와 width의 trade-off를 평가하는 실험이다. 실험을 위해 ImageNet 데이터셋을 사용하였고, ResNext 모델 구성을 위해 단순히 ResNet 모듈을 ResNext 모듈로 교체하였다고 한다.
실험의 결과로 cardinallity가 증가할수록 성능이 개선되었다. 또한, ResNet-50과 ResNext-50을 비교하였을 때, ResNext의 학습이 더욱 빠르게 이루어졌다.
2. Increasing Cardinality vs Deeper / Wider
본 실험은 성능 개선에 width, depth, cardinality 중 무엇이 가장 큰 영향을 미치는지 분석하기 위한 실험이다.

표에서 보이다시피 ResNet-200, ResNet-101, ResNext-101 중 ResNext-101의 성능이 가장 높았다. 즉, cardinality가 성능 개선에 가장 큰 영향을 미쳤다.
3. Residual connections

이 실험은 shortcut connection의 유무가 ResNext의 성능에 영향을 미치는지 판단하기 위한 실험이다. 표에서 보이다시피 shortcut connection이 존재할 때, 성능이 더욱 높았다.
4. Comparisons with state of the art results

ImageNet 데이터셋에서 ResNext는 기존의 SOTA 모델인 Inception-ResNet-v2보다 성능이 우수했다.
Experiments on ImageNet-5k
ImageNet-5k는 ImageNet-22K의 일부다. 테스트셋으로는 ImageNet-1K를 사용하였다.
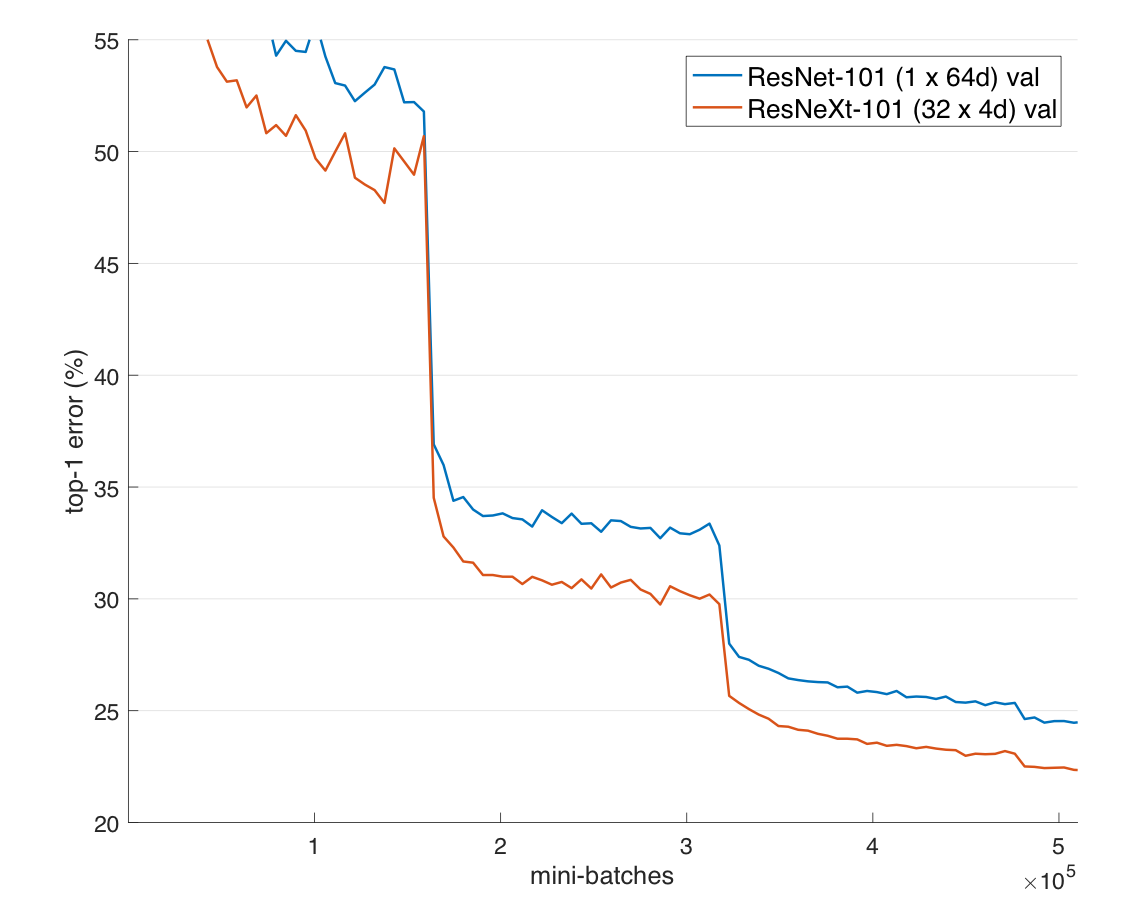
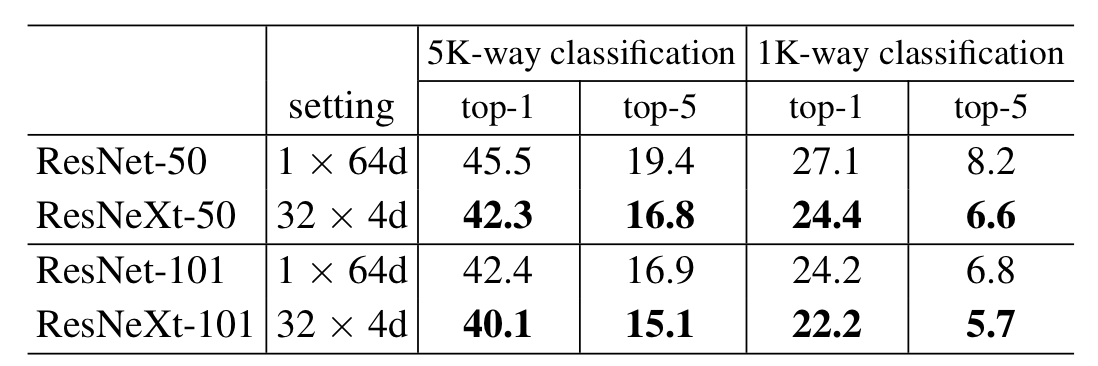
실험의 결과로 ResNet보다 ResNext가 성능이 더욱 우수했다. 이는 ResNext가 더욱 훌륭한 표현력을 가짐을 의미한다.
Experiments on CIFAR
CIFAR 데이터셋에 대해서도 cardinality가 depth, width보다 성능에 큰 영향을 미치는지에 대해 실험을 진행하였다.


ImageNet 데이터와 같이 CIFAR 데이터에 대해서도 cardinality가 성능 개선에 큰 영향을 미쳤다.
Experiments on COCO object detection
Object Detection에서 성능을 평가하기 위해 Object detection 모델로 Faster R-CNN을 사용하였고, back-bone model로 ResNet과 ResNext을 사용하여 성능을 비교하였다.

Object Detection에서도 ResNext가 ResNet보다 뛰어난 성능을 보였다.
Discussion
ResNext는 기존의 ResNet에 Group convolution 개념을 도입하여 cardinality라는 새로운 성능에 영향을 미치는 요소를 고안하였고, 이것이 실험적으로 depth나 width보다 성능 개선에 도움이 됨을 보였다.
'Classification' 카테고리의 다른 글
| [논문 정리] PyramidNet (0) | 2022.12.04 |
|---|---|
| [논문 정리] PolyNet (0) | 2022.12.04 |
| [논문 정리] Xception (0) | 2022.11.27 |
| [논문 정리] SqueezeNet (0) | 2022.11.26 |
| [논문 정리] DenseNet (0) | 2022.11.26 |



