
- Weight initialization
- object detection
- 딥러닝
- image classification
- Optimizer
- SPP-Net
- LeNet 구현
- deep learning
- Convolution 종류
- overfeat
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Today
- Total
I'm Lim
[논문 정리] ShuffleNet v1 본문
Paper
Zhang, Xiangyu, et al. "Shufflenet: An extremely efficient convolutional neural network for mobile devices.". Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
Abstract
ShuffleNet은 제한된 하드웨어 사양을 가진 휴대기기에 특화된 모델이다. ShuffleNet은 Pointwise Group Convolution과 Channel shuffle을 사용하여 정확도를 유지하면서 계산량을 현저히 줄였다. ShuffleNet은 AlexNet의 성능을 유지하면서 13배나 빠른 연산을 한다.
Introduction
지금까지의 Image Classification 모델들을 성능개선을 위하여 모델의 파라미터 수를 키워왔고, 그 결과 수십억이상의 FLOPs를 요구하였다. ShuffleNet은 FLOPs를 수천만 FLOPs 수준으로 낮추는 것을 목표로 하였다 (이는 드론, 로봇, 스마트폰 등에서 처리가 가능한 수준). 즉, 제한된 컴퓨터 성능을 위한 효율적인 네트워크 모델을 고안하는 것이 ShuffleNet의 목표다.
- ShuffleNet의 핵심 아이디어
1 ) 기존의 SOTA라고 불리는 Xception과 ResNext의 1 x 1 Conv에서 연산량이 너무 많이 요구되어 비효율적이라는 것을 발견하였고, 이를 해결하기 위해 Pointwise Group Convolution을 사용하였다.
2 ) Pointwise Group Convolution에서 발생할 가능성이 있는 부작용을 해결하기 위해 Channel Shuffle 연산을 진행하였다.
Approach
1. Group Convolutions
Xception과 ResNext에서 소개된 depthwise seperable convolution이나 group convolution은 훌륭하게 컴퓨터 연산량과 성능의 trade-off 관계를 무너뜨렸다. 하지만, 이 모델들은 1 x 1 Convolution의 엄청난 연산량을 고려하지 않았다.
저자는 이 문제를 해결하기 위해 1 x 1 Convolution도 group convolution내의 연산으로 처리하는 방식을 제안했다. 하지만, 이것은 특정 채널의 출력이 입력 채널의 일부분만을 반영하게 되는 문제를 야기하게 된다 (이러한 성질은 정보의 그룹간의 정보 흐름을 방해하고, 표현력을 감소시킨다).

2. Channel Shuffle
그림의 (b)와 같이 채널을 여러 세부 그룹으로 나눈 뒤, 각 3 x 3 Conv의 입력으로 사용하면 위에서 제기한 문제를 해결할 것이다. 이를 Channel Shuffle 연산이라 한다.
ShuffleNet Unit
위 그림에서 Spatial Resolution을 유지할 때에 (b)의 모듈을 사용하고, Down sampling을 진행할 때는 (c)의 모듈을 사용하는 구조로 ShuffleNet은 구성되었다.
ShuffleNet은 이러한 모듈 덕분에 ResNet과 ResNext에 비해 제한된 컴퓨터 성능에서 더 많은 채널 수를 사용할 수 있다. 이는 작은 모델에서 매우 중요한 요소라고 한다.
ShuffleNet Architecture
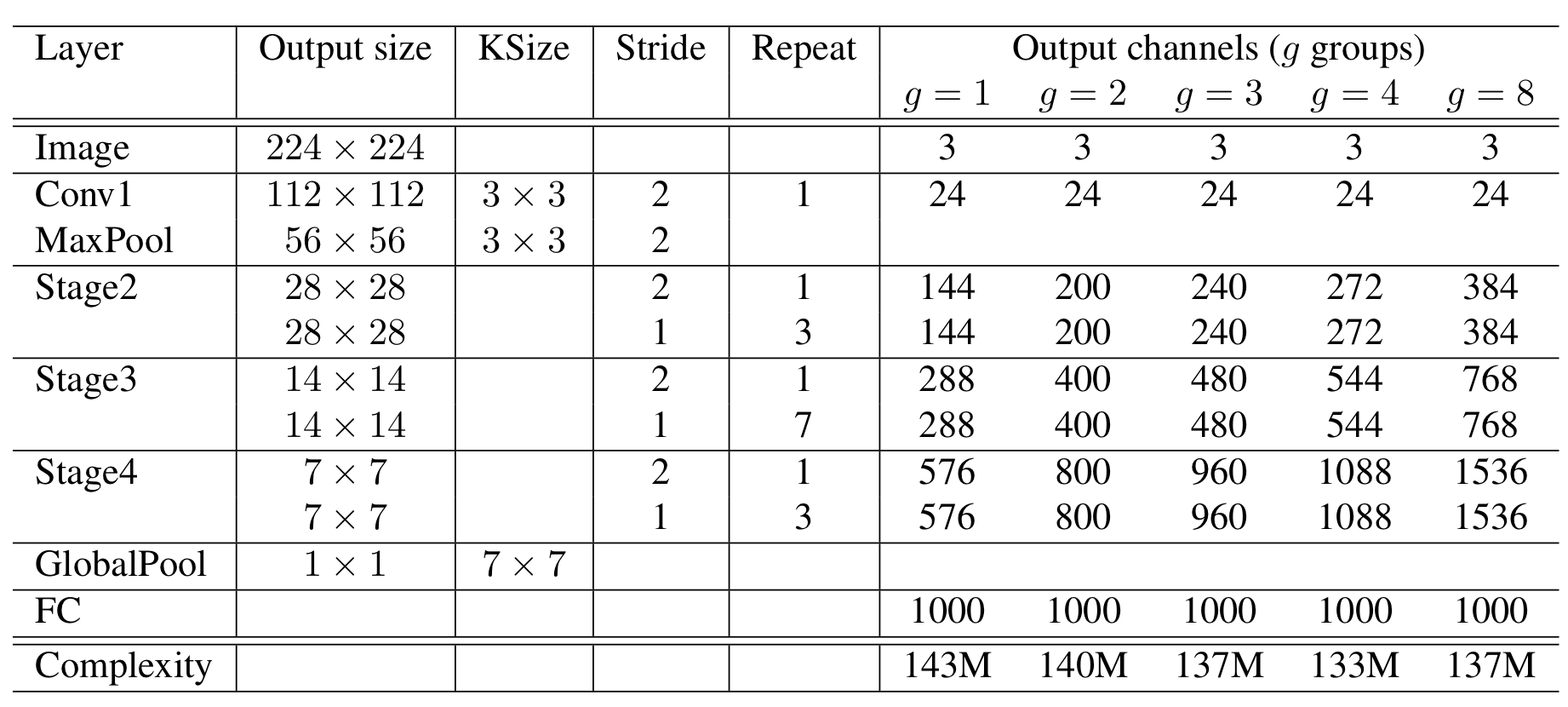
1 ) ShuffleNet은 위와 같이 feature map 사이즈는 점점 줄어들고, 채널의 개수는 점점 커지는 구조를 가진다.
2 ) 140 MFLOPs를 유지하면서 cardinality를 하이퍼 파라미터로 두고, 여러가지 구조를 생성하였는데 cardinality를 키울수록 성능이 개선되었다고 한다.
Details of Learning
1. Dataset : ImageNet 2012
2. training settings and hyper-parameters : ResNext와 동일
1 ) weight decay : 4e-5
2 ) linear decay learning rate : 0.5 to 0
3 ) Data Augmentation : MobileNet과 동일
Ablation Study
1. Pointwise Group Convolutions

ShuffleNet Architecture에서 Cardinality를 하이퍼 파라미터로 두고, 여러 모델을 생성하였다고 했다. 이를 학습시킨 결과가 위의 표와 같다. 보이다시피, Cardinality가 증가할수록 성능이 계속 개선되는 것을 볼 수 있다. 또한, 크기가 작은 모델이 Cardinality의 영향을 더욱 크게 받는 것을 확인하였다.
2. Channel Shuffle vs No Shuffle
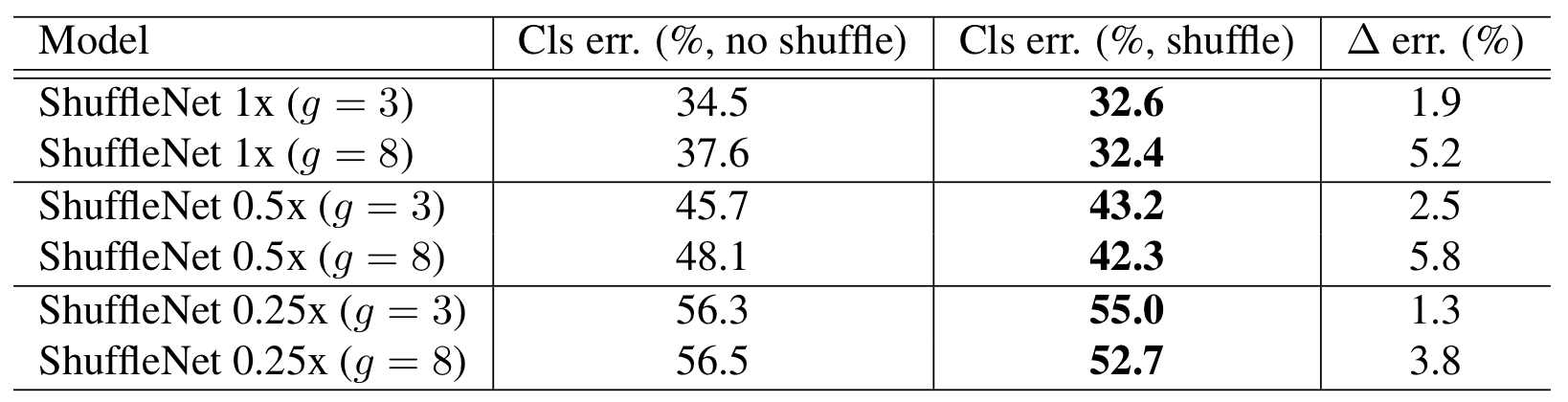
위 Ablation Study는 Channel Shuffle이 성능에 어떠한 영향을 미치는지 확인하기 위함이다. 결과에서 보이다시피, Channel Shuffle을 진행하는 것이 모델의 크기와 관계없이 성능을 훨씬 개선시켰다.
Comparison with Other Structure Units

이 실험은 다른 모델들과 ShuffleNet의 성능을 비교하는 실험이다. 공정한 평가를 위하여 MFLOPs를 유사하게 맞추고, 성능을 비교하였다. 결과는 ShuffleNet이 가장 우수하였다. 흥미로운 점은 채널의 수와 성능이 비례하였다고 한다.
Comparison with MobileNets and Other Frameworks
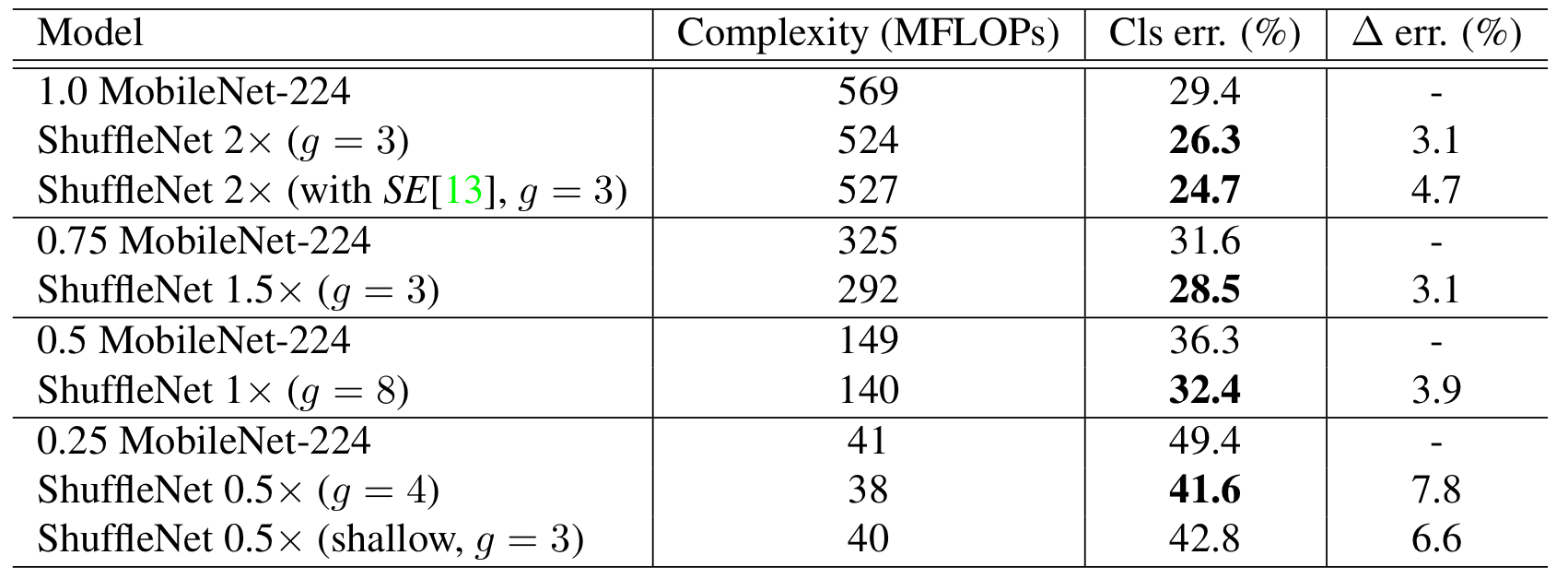
이 실험은 MobileNet와의 비교를 위한 실험이다. 보이다시피, Complexity 스코어, Classification 성능 모두 ShuffleNet이 앞서는 것을 확인하였다.
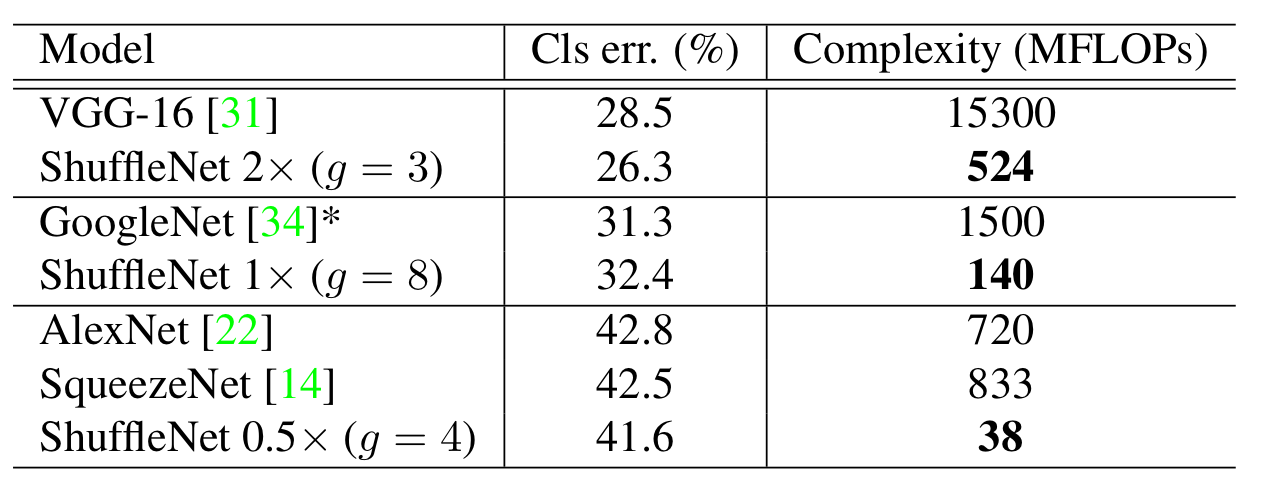
다음으로, 유명 모델들과 ShuffleNet과의 비교를 진행하였다. 월등히 낮은 Complexity를 가지고도 Classification 성능이 유사한 것을 확인하였다.
Generalization Ability
여기서 말하는 Generalization Ability는 다른 분야에 적용하였을 때, 얼마나 성능을 잘 내는지에 관한 내용이다. 이를 위해, Faster-RCNN을 이용한 Object Detection 과제를 수행하여 MobileNet과 비교하였다.

보이다시피, MobileNet과 유사한 Complexity를 가지는 ShuffleNet 2x는 성능이 MobileNet보다 월등히 높았다.
또한, MobileNet Complexity의 1/4를 가지는 ShuffleNet 1x은 MobileNet과 거의 유사한 성능을 보였다. 이를 통해, MobileNet보다 ShuffleNet이 Generalization Ability가 좋음을 알 수 있다.
Actual Speedup Evaluation
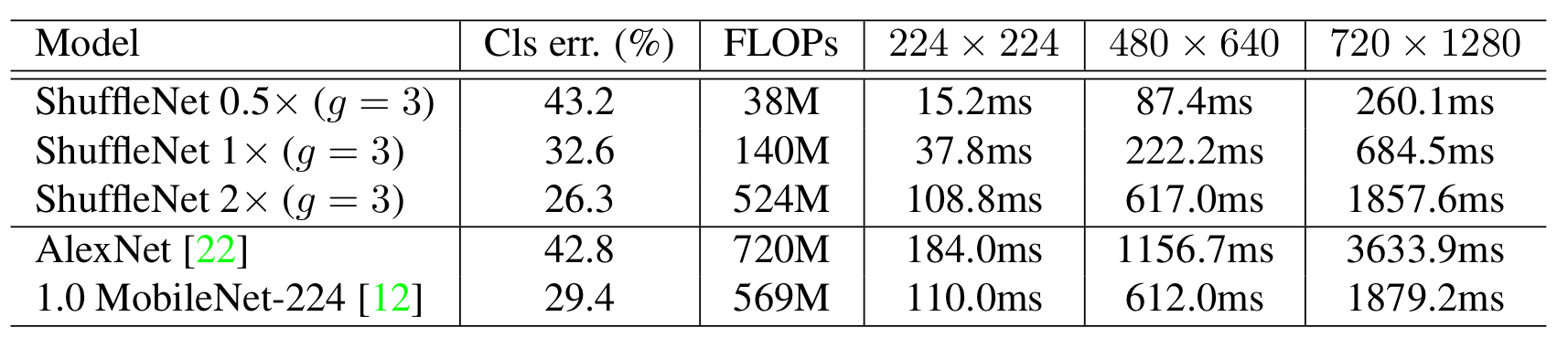
마지막으로 실제 ARM 프로세서 기반의 휴대기기에서의 속도를 비교하였다고 한다.
1 ) ShuffleNet 0.5x가 AlexNet과 유사한 성능을 가짐에도 거의 13배의 연산속도를 보인다.
2 ) ShuffleNet 2x는 MobileNet과 연산속도가 유사하지만, 성능이 높다.
Discussion
ShuffleNet은 Xception과 ResNext의 아이디어인 Depthwise Seperable Convolution을 유지함과 동시에 연산량을 줄임으로써 MobileNet보다 적거나 유사한 연산속도를 가지면서 성능을 더욱 개선시켰고, AlexNet보다는 13배나 빠르 연산속도를 보였다.
'Classification' 카테고리의 다른 글
| [논문 정리] CondenseNet (0) | 2022.12.12 |
|---|---|
| [논문 정리] SENet (0) | 2022.12.12 |
| [논문 정리] PyramidNet (0) | 2022.12.04 |
| [논문 정리] PolyNet (0) | 2022.12.04 |
| [논문 정리] ResNext (0) | 2022.11.28 |



