
- overfeat
- Optimizer
- object detection
- 딥러닝
- Convolution 종류
- Weight initialization
- SPP-Net
- image classification
- LeNet 구현
- deep learning
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Today
- Total
I'm Lim
[논문 정리] DenseNet 본문
Paper
Huang, Gao, et al. "Densely connected convolutional networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
Abstract
ResNet 논문에서 레이어 간 shortcut connection을 이용하였을 때 더욱 안정적이고, 빠르게 학습 함을 보였다. ResNet이 레이어 간의 shotcut connection을 가지는 구조라면, DenseNet은 이전 모든 레이어와 현재 레이어에 shortcut connection을 가지는 구조다. 따라서, ResNet의 shortcut connection의 개수가 $L$개라면, DenseNet은 $\dfrac {L(L+1)}{2}$개다.
Introduction
CNN 모델이 깊어짐에 따라, 입력에 관한 정보가 모델의 후반부에는 사라지거나, back-propagation value가 모델의 초반부에서 사라질 가능성이 있다. ResNet은 이 문제를 해결하기 위해서 레이어에서 레이어로 short connection을 하었다.
DenseNet은 레이어간 정보의 흐름이 최대가 될 수 있도록 모든 레이어 간에 short connection을 하였다.
ResNet은 레이어의 입력과 출력을 element-wise add를 진행하였지만, DenseNet은 concatenation을 진행하였다.
Related Work
논문 발표당시에 대표적인 Image Classification 모델은 GoogLeNet과 ResNet이었다.
GoogLeNet은 네트워크의 width를 증가시킴으로써 성능을 개선하였고, ResNet은 네트워크의 depth를 통해 성능을 개선하였다.
DenseNet은 width나 depth보다 feature reuse를 통해서 좀 더 응축된 모델을 만들고자 하였다.

각기 다른 레이어에서 학습된 feature map들을 concatenation하는 것은 레이어의 입력의 다양성을 증가시키고, 효율성을 증가시킨다.
이것이 DenseNet과 ResNet의 가장 큰 차이점이라고 한다.


위 수식에서 보이다시피, DenseNet의 L번째 레이어의 입력은 L-1번째까지의 feature map들을 모두 concatenation시킨 것을 볼 수 있다.
DenseNet
1. Composite function
DenseNet의 module 구조는 pre-activation ResNet 논문에서 그러하였듯이, [ BN - ReLU - Weight ] 순서로 이루어져있다.
2. Pooling Layers
당연한 소리겠지만, feature map사이즈가 바뀌게 되면 concatenation이 불가능해진다 ( padding을 안한다는 가정하에 ). 따라서, DenseNet은 feature map 사이즈가 줄어드는 기준으로 Dense Block을 나눈다.

또한, Dense Block들 사이에 있는 레이어들을 transition layer라고 부른다.
이 transition layer는 [ BN - 1 x 1 Conv - 2 x 2 average Pooling ]으로 이루어진다.
3. Growth rate
만약 하나의 Dense module이 k개의 feature map을 만든다면, L번째 레이어는 $k_0 + k \: (l-1)$의 feature map을 입력으로 갖는다 ($k_0$ 는 입력 이미지의 채널 수 ). 이 때, k를 growth rate라고 한다.
4. Bottleneck Layer
각 레이어의 입력은 이전 레이어들의 concatenation이기 때문에 많은 수의 채널을 가질 수가 있다. 이는 computational cost를 키우게 될 것이므로 1 x 1 Conv를 이용하여 채널의 개수를 줄인다. 이 1 x 1 Conv를 bottleneck layer라고 한다.
논문에서는 [ BN - ReLU - Conv ( 1 x 1 ) - BN - ReLU - Conv ( 3 x 3 ) ]구조를 사용하였고, 1 x 1의 채널의 수는 4 x k로 사용하였다.
이렇게 채널의 수를 줄이기 위해 Bottleneck Layer를 사용하는 구조를 DenseNet-B라 한다.
c.f.) Bottleneck layer : 1 x 1 Conv의 목적은 채널의 개수를 줄이는 것이다. 물론, Inception V2에서 1 x 1 Conv 후, Spatial aggregation을 진행하면 정보의 손실이 크지 않을 것이라고 하였지만, 그럼에도 정보의 손실이 존재하는 것이다. 이러한 이유로 저자는 Bottleneck Layer라고 명명했으리라 추측한다.
5. Compression
위에서 설명했던 transition layer는 Spatial aggregation을 위함이다. 만약 translayer의 입력 채널 수가 $m$이라 하고, $\theta$를 compact factor라고 하였을때, transition layer를 거친 후의 출력 채널 수를 $\theta_m$이라 한다. 따라서, $\theta$가 1이라면 입력 채널의 수와 출력 채널의 수 모두 $\theta_m$ = $m$이다.
$\theta$를 1보다 작은 값으로 지정하였을 때를 DenseNet-C라 한다.
만약, Bottleneck Layer와 $\theta$를 1보다 작은 값을 갖는 trainsition layer를 사용하면 이를 DenseNet-BC라 한다.
6. Implementation Details
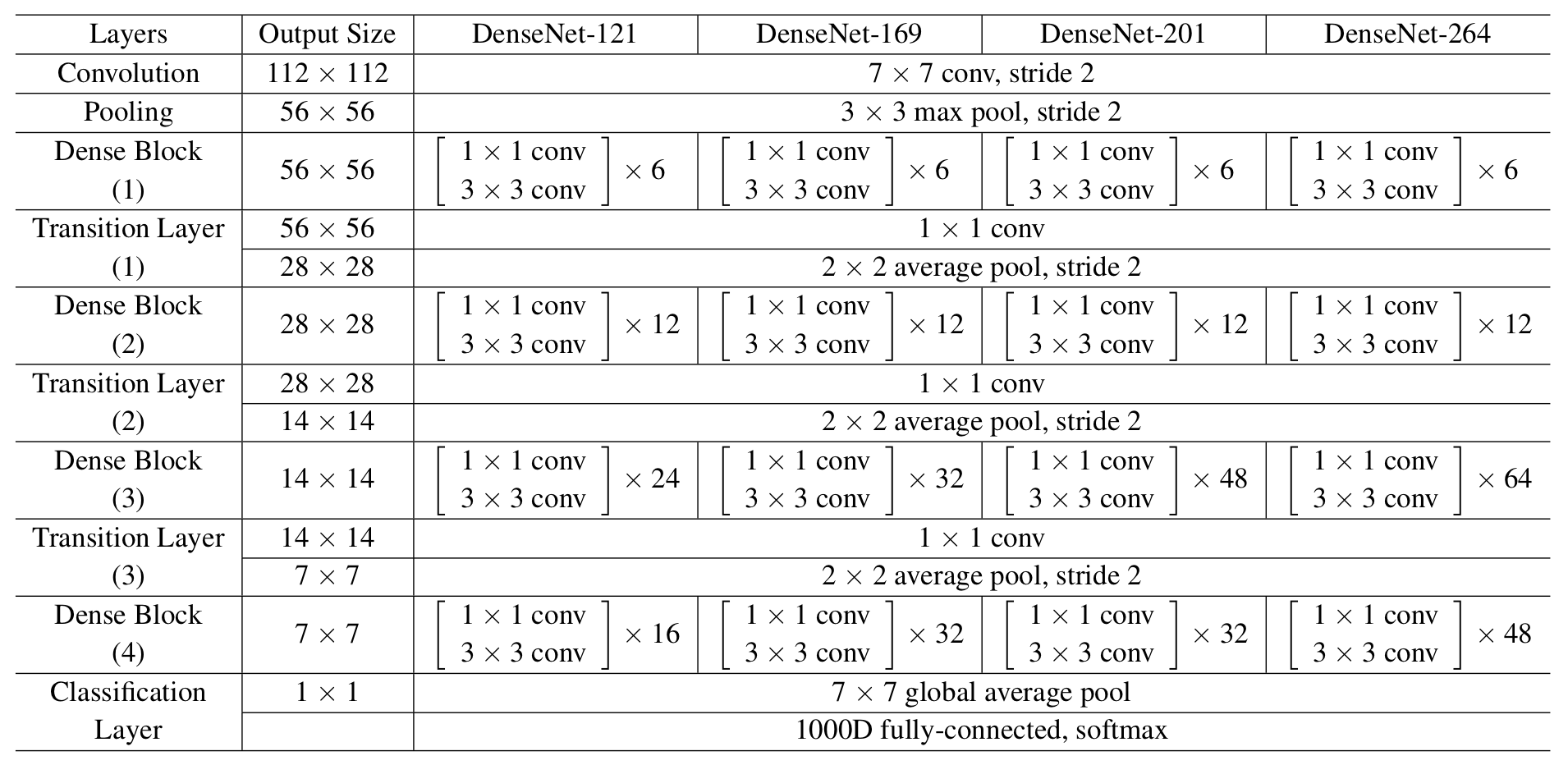
위의 표는 ImageNet을 학습시키기 위한 DenseNet-BC구조다.
Dataset
1. CIFAR
CIFAR 데이터셋의 전처리를 위해서 GCN을 사용하였다. 또한, Augmentation은 ResNet에서 그랬듯이 Scale jittering을 사용하였고, Augmentation을 사용한 데이터셋은 '+' 부호를 붙였다고 한다.
2. SVHN
SVHN 데이터셋의 전처리를 위해서 255를 각 픽셀에 나누어줌으로써 scaling을 진행했다. Augmentation은 진행하지 않았다고 한다.
3. ImageNet
ImageNet 데이터셋의 Augmentation은 ResNet에서 사용한 것과 동일하게 진행했다. 테스트를 위해서 VGGNet에서 사용한 Single-Crop 기법과 ResNet에서 사용한 10-Crop 기법을 사용했다.
Details of Learning
1. Optimizer
SGD ( with Nesterov momentum 0.9 )로 사용하였다. Batch size는 CIFAR, SVHN은 64로, ImageNet은 256으로 설정하였다.
2. Weight Initialization & decay
Weight Initialization을 위해서 Kaming He initialization을 적용하였고, Weight decay는 $10^{-4}$로 설정하였다.
3. Learning rate
- CIFAR, SVHN은 learning rate를 0.1로 설정하였다. epoch의 50%, 75%를 지날 때, learning rate를 10만큼 나눠주었다.
- ImageNet은 learning rate를 0.1로 설정하였다. epoch이 30, 60을 지날 때, learning rate를 10으로 나눠주였다.
Result
1. CIFAR, SVHN
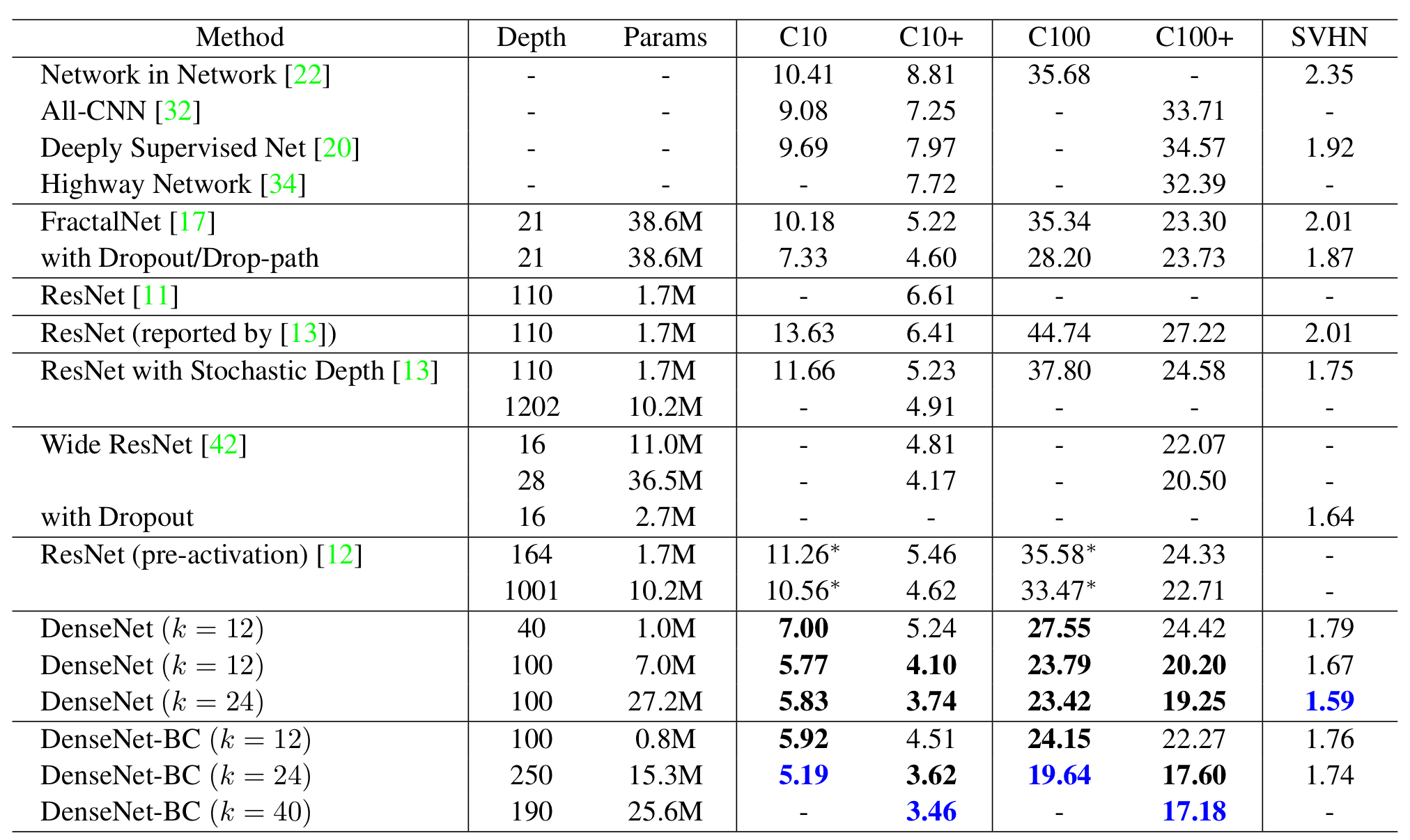
표에서 나타난 것과 같이 DenseNet이 가장 우수한 성능을 보였다.
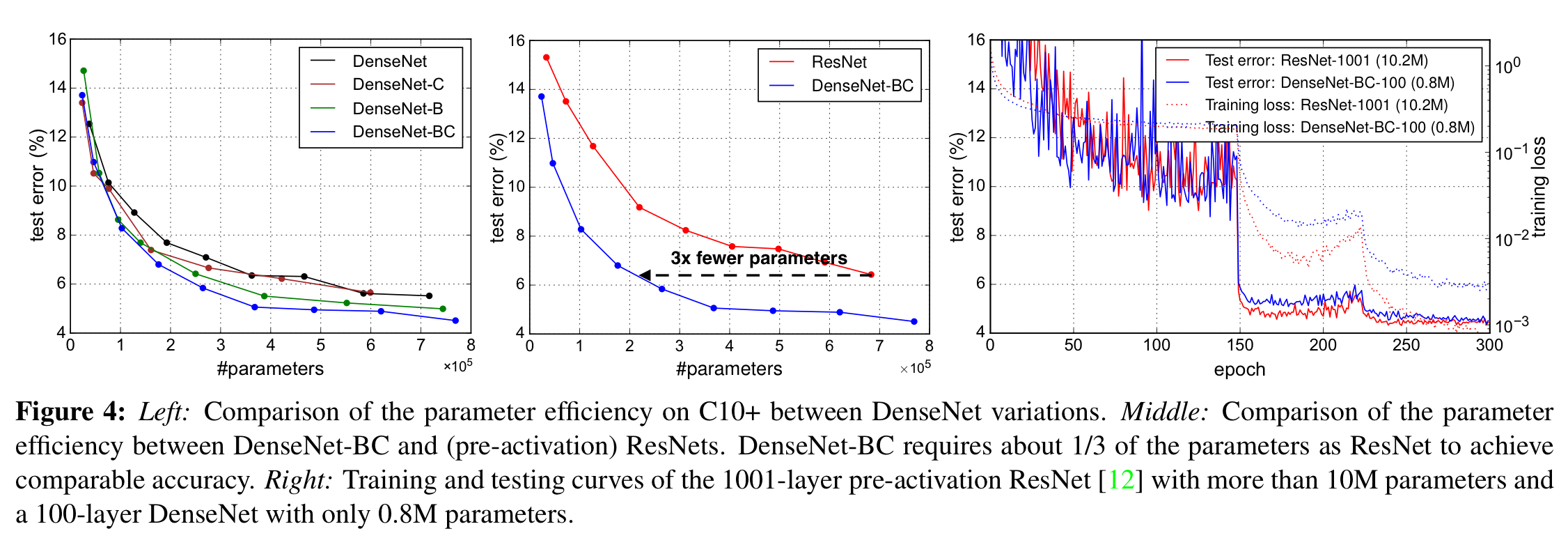
또한, ResNet-1001과 DenseNet-BC ( 100 )을 비교하였을 때, 훨씬 더 적은 파라미터 수로 빠르게 수렴함을 보였다.
2. ImageNet
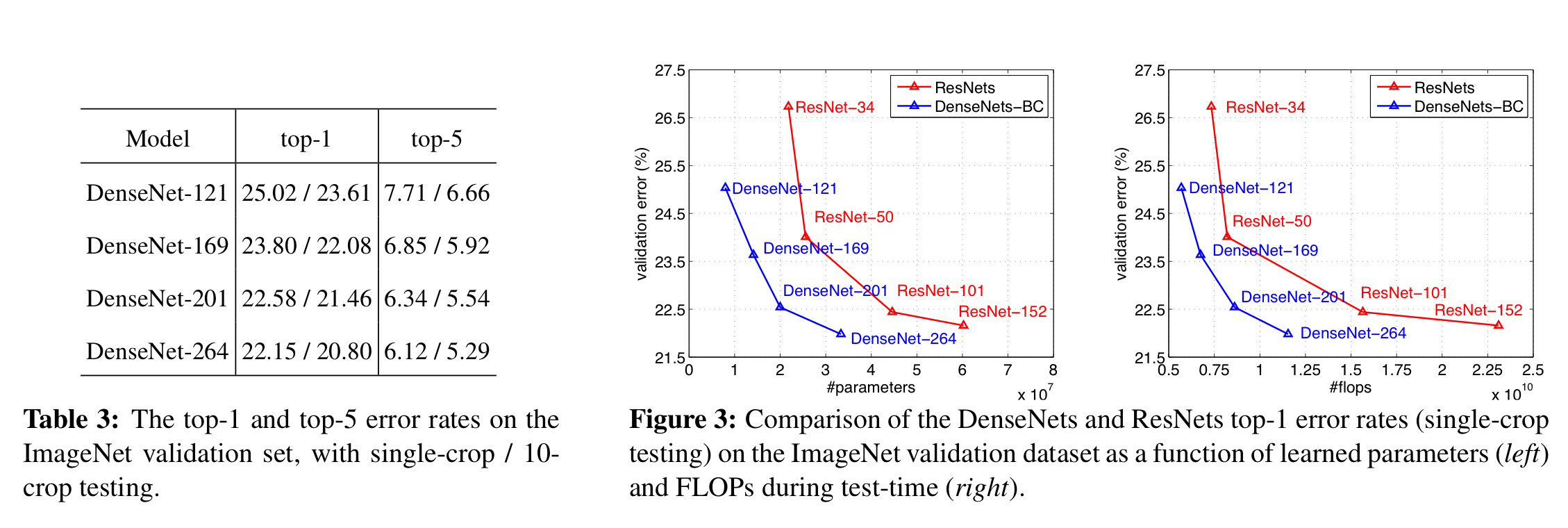
ImageNet 데이터에 대해 DenseNet 역시 레이어가 깊어질수록 성능이 증가하였고 ( Table 3 ), ResNet에 비해 더 적은 파라미터 수로 더욱 우수한 성능을 보였다 ( Figure 3 ).
Feature Reuse
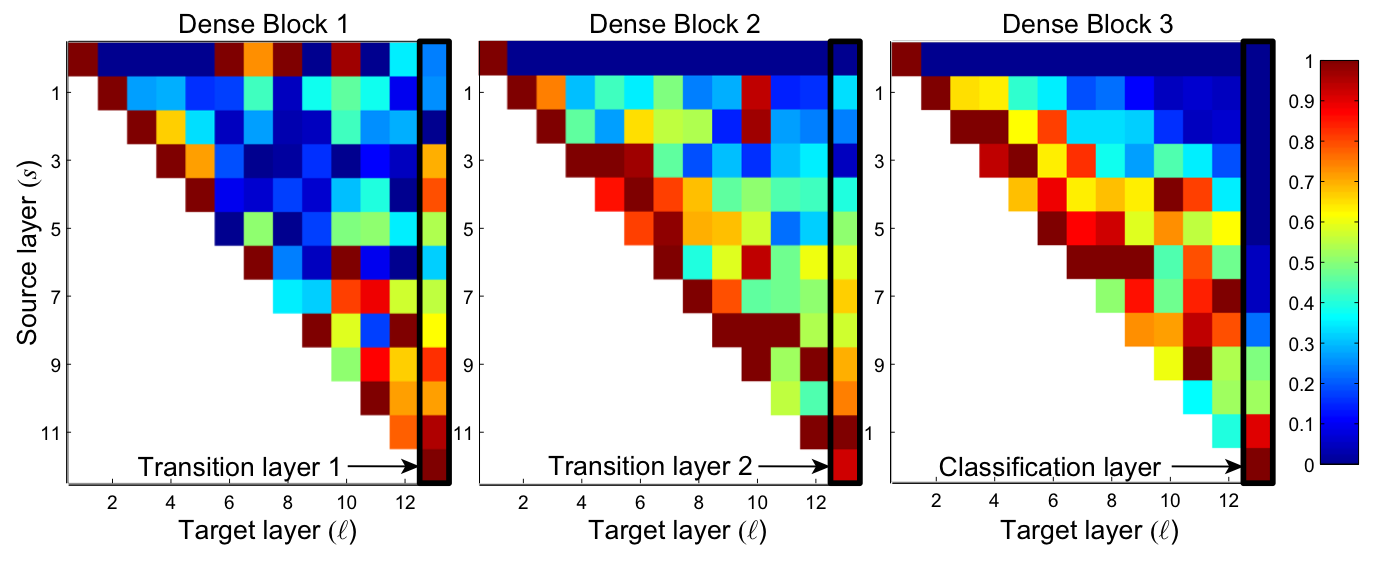
DenseNet은 그 구조상 모든 이전 레이어의 feature map을 사용할 수 있다. 저자는 학습된 모델이 이러한 장점을 활용하는지 알아보고자 실험을 진행하였다.
1. Process
1. C10+를 L=40, k = 12 DenseNet 모델에 학습시킨다 ( DenseNet-BC 아님 ).
2. 한 block 내 l번째 conv layer와 연결된 s와의 weight 평균을 구하였다.
2. Result
위 그림에서 (l, s) 위치는 l번째 레이어가 얼마나 s번째 레이어의 feature map을 많이 반영하는지를 나타낸다.
1. 한 block 내 초기 레이어에서 추출된 feature map을 같은 block 내 후반부 레이어에서 사용된다.
2. 그림의 맨 오른쪽 열을 보면 값이 0인 지점이 많이 없다. 즉, transition layer가 대부분의 feature map을 사용한다.
3. 두 번째, 세 번째 dense block에서 transition layer에 대한 첫 번째 행의 영향이 가장 적은 것을 볼 수 있는데 이는 transition layer가 불필요한 feautre들을 많이 출력한다는 의미가 된다. 이러한 정보는 DenseNet-BC에서는 압축이 될 것이고, 따라서 성능이 좋아진다고 한다.
4. Classification Layer에서는 후반부의 feature map을 많이 사용한다. 이는 high-level feature가 이 네트워크의 후반부에서 extract됨을 보여준다.
Discussion
DenseNet은 ResNet의 구조와 매우 유사하지만, Block 내 모든 레이어 간 shortcut connection이 있다는 점이 가장 큰 차이다. feature map을 재사용함으로써 학습을 안정화시켰고, 그 결과 파라미터 수가 줄였음에도 ResNet만큼의 성능 혹은 더욱 좋은 성능을 보였다.
'Classification' 카테고리의 다른 글
| [논문 정리] Xception (0) | 2022.11.27 |
|---|---|
| [논문 정리] SqueezeNet (0) | 2022.11.26 |
| [논문 정리] Inception v4 (0) | 2022.11.20 |
| [논문 정리] Pre activation ResNet (0) | 2022.11.20 |
| [논문 정리] ResNet (0) | 2022.11.20 |



