
- 딥러닝
- Optimizer
- SPP-Net
- image classification
- LeNet 구현
- deep learning
- object detection
- overfeat
- Convolution 종류
- Weight initialization
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Today
- Total
I'm Lim
[논문 정리] SENet 본문
Paper
Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
Abstract
Xception이나 ResNext 등의 논문에서 제시한대로 이미지를 cross-channel correlation과 spatial correlation으로 나눠볼 수 있다면, 지금까지의 Image Classification 모델들은 Spatial correltation을 잘 처리하여 표현력을 증가시키는 방법을 연구해왔다고 볼 수 있다. SENet은 channel 방향의 channel correlation에 집중하여 표현력을 증가시키는 방법을 연구하였다.
Introduction
SENet은 채널을 재보정함으로써 전체 학습 데이터셋 (global information)에 유용한 특징들을 강조하고, 그렇지 않은 특징들을 억누르는 효과를 갖는 모델을 제안한다. 이를 위해, Squeeze 연산에서는 feature map을 GAP를 이용하여 압축시키고, 그 이후 Excitation 연산을 이용하여 적절한 가중치를 구하고, 각 채널에 곱한다.
흥미로운 점은 SENet의 초기 레이어에서는 물체의 종류와 관계없이 (class-agnostic) 유용한 정보를 검출하고 low-level의 표현을 강화하는 반면, 후기 레이어에서는 물체의 종류에 관련된 특징들을 추출한다는 점이다.
SENet는 두가지의 장점을 가진다.
1 ) SE block 자체가 간단하고, 기존 모델에 모듈을 교체하는 방식으로 사용이 가능하다.
2 ) SE block은 컴퓨터 연산량이 적고, 모델 복잡도를 아주 약간 높인다.
Related Work
Xception과 ResNext의 Group convolution은 cross-channel correlation과 spatial correlation이 분리가 가능하다는 가정하에 모델의 복잡도와 컴퓨터 계산량을 줄이기위한 목적에 집중하였다. 그러나, SENet은 명시적으로 채널 간의 correlation을 다룸으로써 학습 과정을 쉽게 만들고, 표현력을 증가시키는 데에 집중하였다.
Squeeze and Excitation blocks
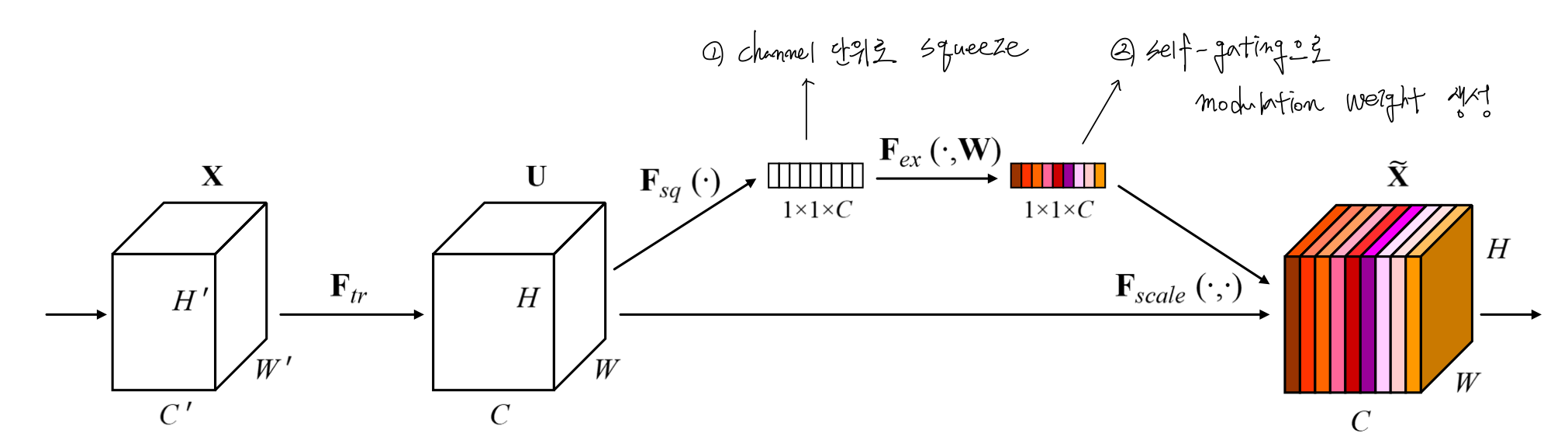

위 식은 $X$에서 $U$로 가는 연산과정을 수식화한 것이다. $\large {v_c^s}$는 1개의 채널을 s번째 가진 커널이고, $\large {x^s}$는 그 커널에 대응되는 feature map이다. 그 이후에, global information에 접근하여 유용한 특징을 추출하기 위해서 SE block을 사용한다.
1. Squeeze : Global Information Embedding
global spatial information을 구하기 위해 SENet에서는 Squeeze 연산 때 global average pooling을 사용하여 channel-wise statistics를 생성한다. 이를 수식화하면 아래와 같다.

2. Excitation : Adaptive Recalibration
global spatial information을 사용하기 위해 SENet은 두가지 기준을 제시한다.
1 ) global spatial information은 유연해야 한다 (즉, 채널간의 비선형적인 상호작용을 학습할 수 있어야 한다).
2 ) global information은 상호배타적이지 않다.
이를 만족시키기 위해, SENet에서는 sigmoid를 이용한 simple gating mechanism을 사용하였다. 이를 수식화 하면 아래와 같다.
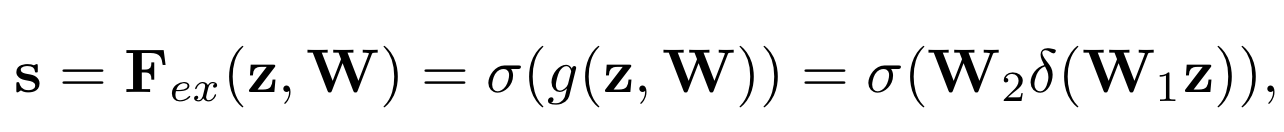
$\large {\delta}$ 는 ReLU연산을 뜻하고, $W_1$과 $W_2$는 fully connected layer를 뜻한다.
$W_1$에서 채널의 개수를 감소시키고, $W_2$에서 다시 채널의 수를 증가시킨다.
이 때, 감소된 채널의 수를 $r$이라는 하이퍼 파라미터로 사용하였다.
따라서, Excitation 전과정은 아래의 식으로 이루어진다.
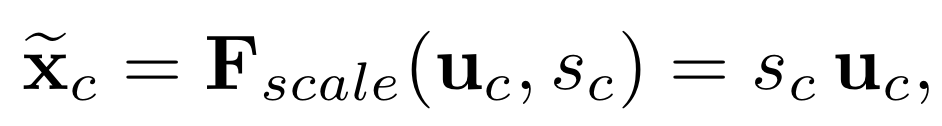
주의할 점은 $\large {F_{scale}}$이 스칼라 값 $S_c$와 feature map $\large{\textbf{u}_c}$의 채널 별 연산을 진행한다는 점이다.
따라서, 정리하면 SE Block은 아래의 그림과 같이 나타낼 수 있다.
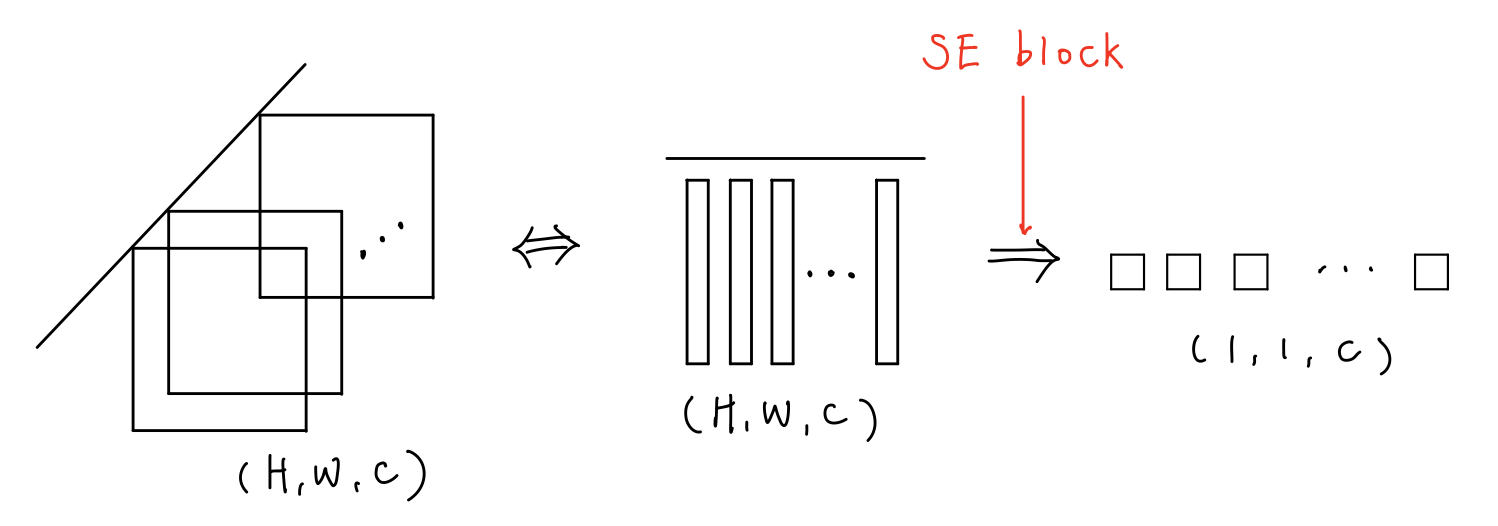
3. Instantiations
SE block은 VGG와 같은 기본적인 네트워크 구조의 Convolution 연산 뒤에 끼워넣을 수 있다.
이 방식으로 SE-Inception 모듈과 SE-ResNet 모듈을 생성하였고, 아래의 그림과 같다.
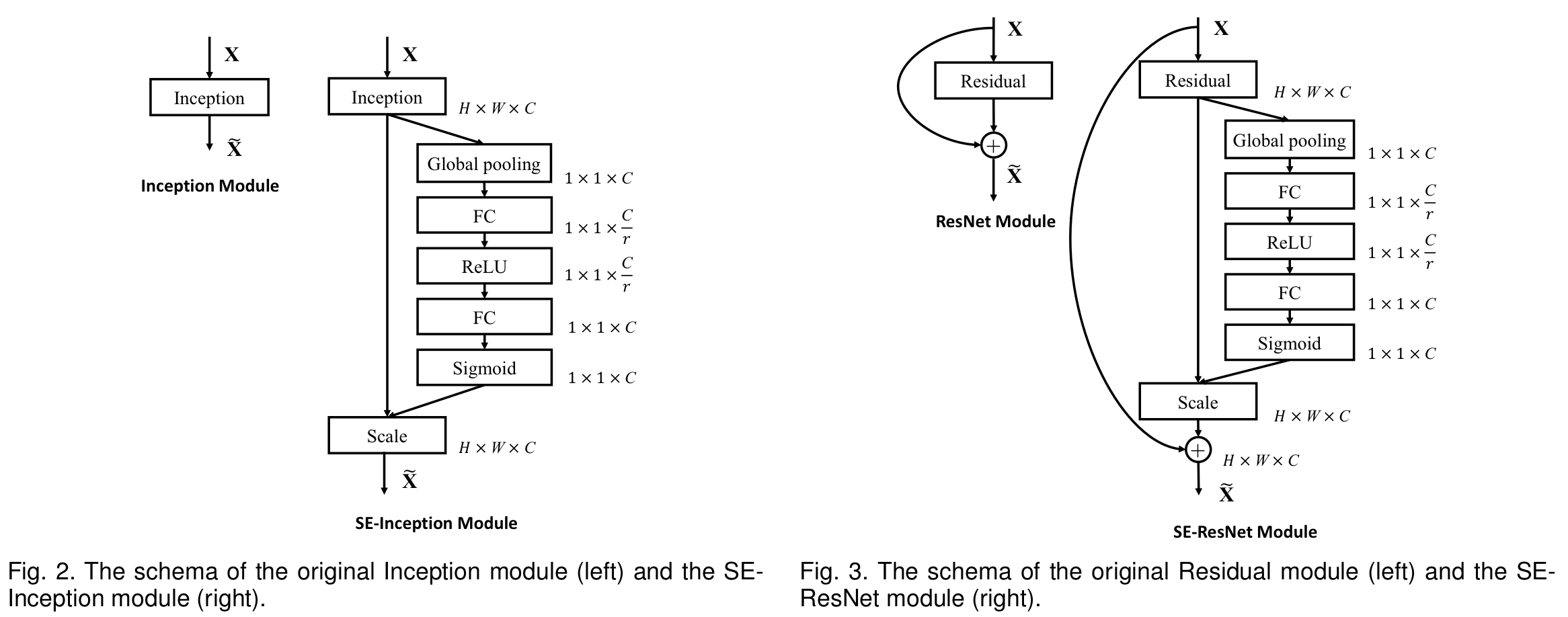
이를 도표화하면 아래와 같다.
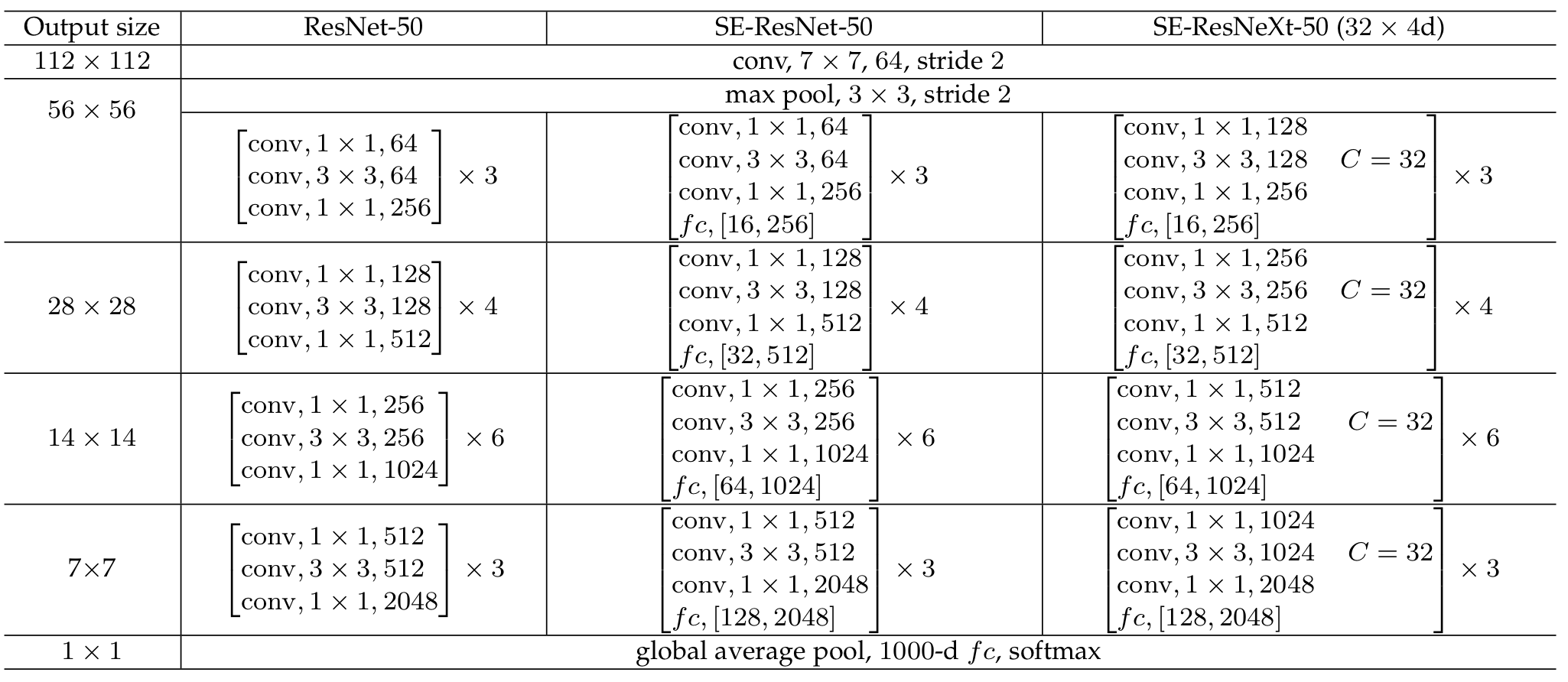
Model and Computational complexity
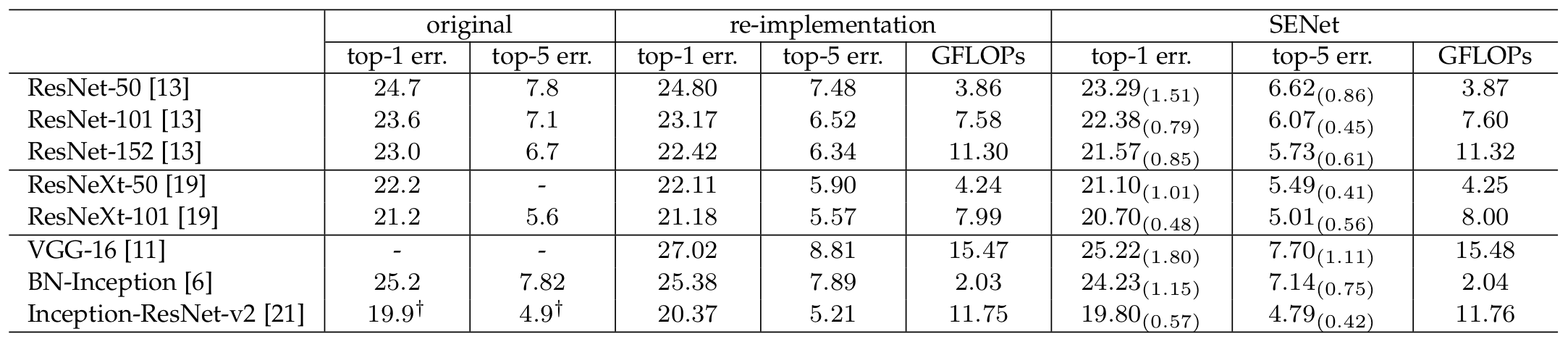
당연히, 기존의 모델 Conv연산 뒤에 SE block을 끼워 넣는 방식이기 때문에 FLOPs는 증가하게 된다. 그러나, FLOPs의 증가보다 성능 개선이 더욱 크게 개선되었다고 한다.
Experiments
1. Image Classification
- 학습을 위해 GoogLeNet의 scale jittering을 사용하였고, random horizontal flipping을 data augmentation으로 사용하였다. 또한, 데이터를 Normalize하였다.
- Optimizer는 momentum을 이용한 SGD를 사용하였다. momentum은 0.9로 설정하였고, batch size는 1024를 사용하였다.
- Learning rate는 초기 값으로 0.6을 설정하고, 30 에폭마다 10으로 나눠주었다.
- 채널의 감소와 관련된 파라미터인 $\large{r}$은 16으로 사용하였다고 한다.
Network depth
위 표를 보면 알 수 있듯이, SE block을 사용하여도 모델의 깊이가 깊어질수록 성능이 지속적으로 증가하였다. 또한, 깊이와 크게 상관없이 기존 모델과의 성능차이가 지속적임을 확인할 수 있다.
Integration with modern architectures

위 그림에서 보이다시피, 학습과정 내내 SE block을 사용한 모델의 성능이 더욱 좋음을 알 수 있다.
Mobile setting

위 그림은 SENet이 모바일 환경에서도 적은 FLOPs의 증가로 성능을 개선시킴을 보여준다.
CIFAR 10 & CIFAR 100
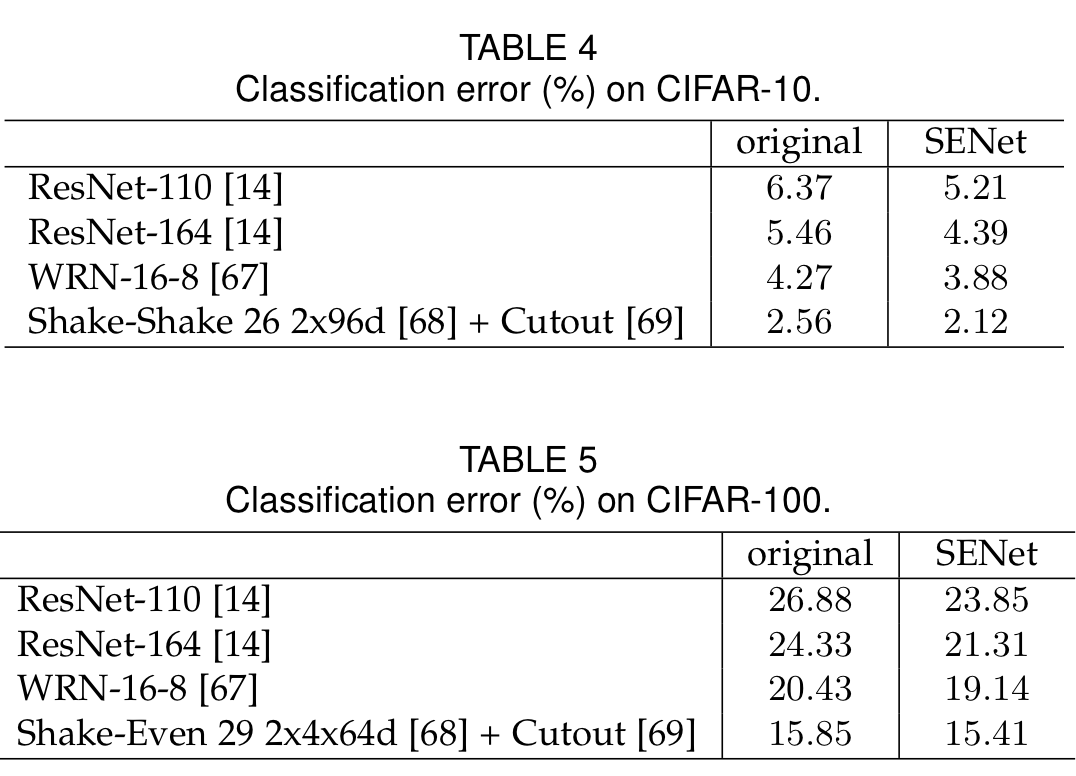
CIFAR 10과 CIFAR 100 데이터 셋에 대해서도 SENet이 기존의 모델보다 성능이 개선됨을 보여준다.
ILSVRC 2017 Classification Competition
ResNext모델을 수정한 네트워크인 SENet-154을 사용하여 참가한 ILSVRC 2017 대회에서 SENet-154가 SOTA를 달성하였다. 이 기록은 보편적으로 사용되는 multi-scale과 multi-crop 기법을 사용하여 평가하였다고 한다.
또한, ILSVRC 2017 이후 ResNext-101 32 x 48d를 이용한 SENet으로 성능을 한번 더 개선시켰다고 한다.
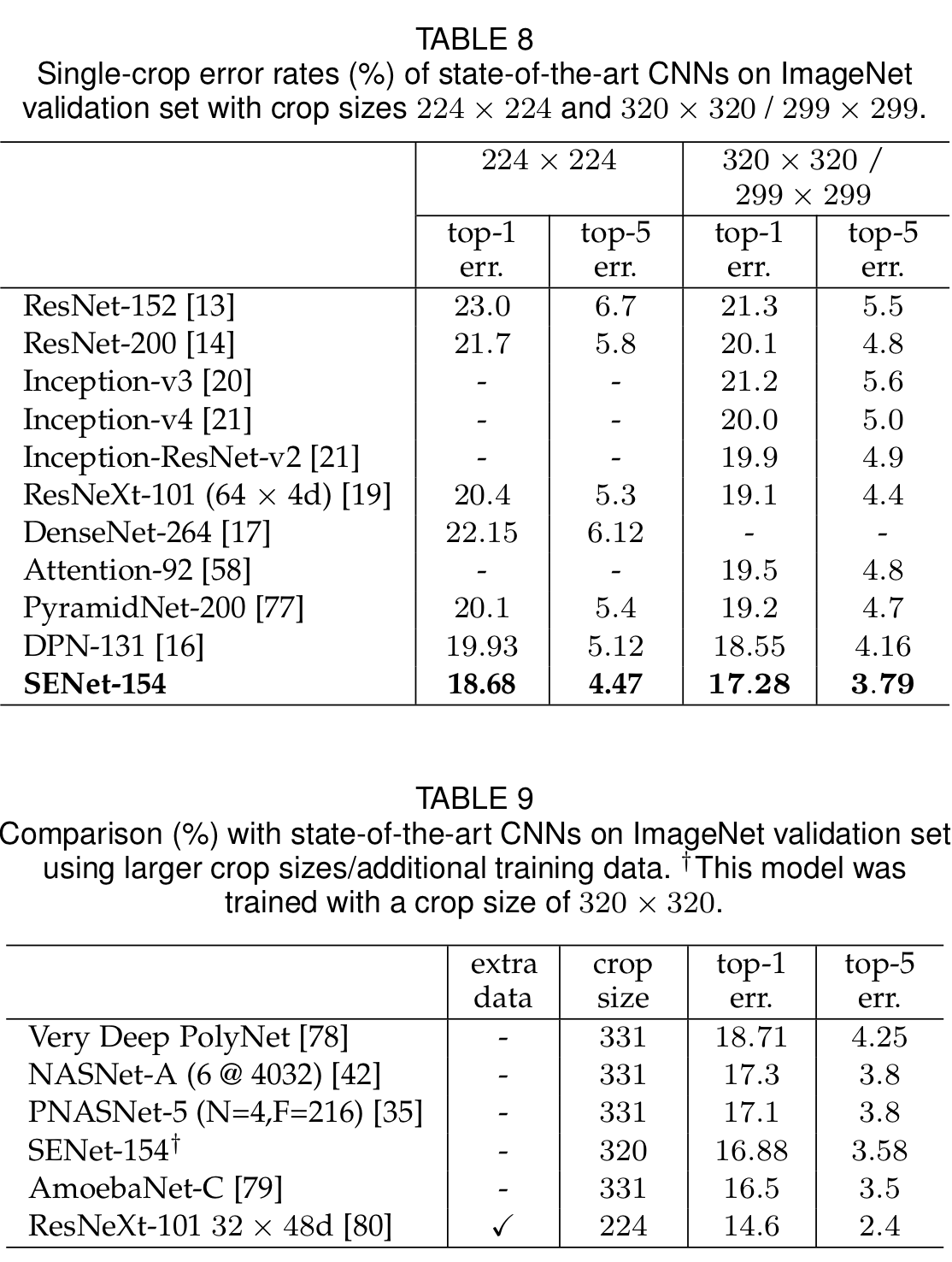
Ablation study
향후 진행되는 모든 ResNet-50을 backbone 모델로 사용하였다. 추가적으로 학습 시에 Label smoothing을 사용하였다고 한다.
1. Reduction ratio
이 실험은 위에서 말했던 $r$에 따른 성능의 차이를 비교하기 위함이다.
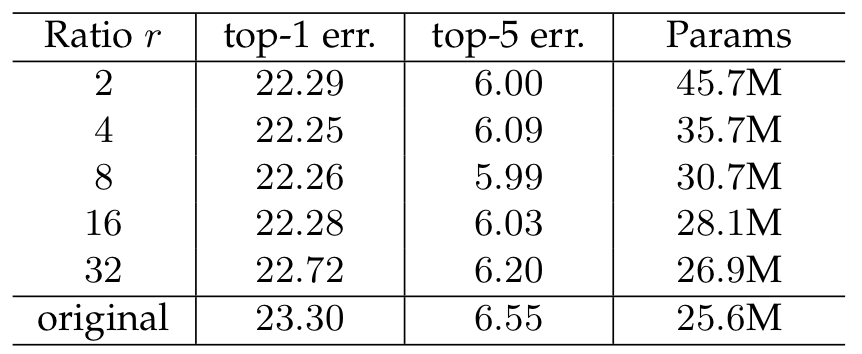
보이다시피, 모델 복잡도와 성능을 모두 고려했을 때 $r$이 16일 때 가장 우수했다.
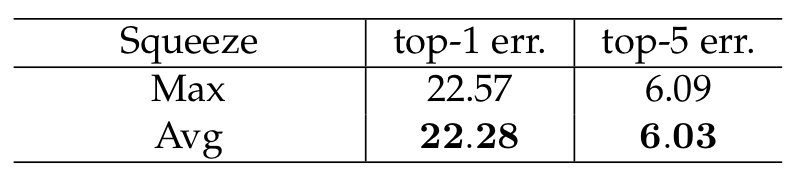
2. Squeeze Operator
이 실험은 squeeze 연산시에 global average pooling을 사용하는 것이 좋을지, global max poolin을 사용하는 것이 좋을지 비교해보는 실험이다. 결과는 global average pooling이 조금 더 나았다.
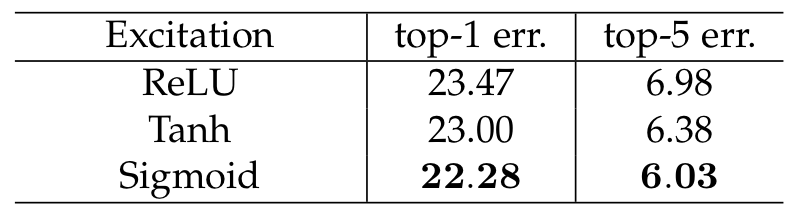
3. Excitation Operator
이 실험은 ResNe-50을 수정하여 만든 SE-ResNet-50으로 진행을 하였다. 실험의 목적은 Excitation에서 어떤 활성화 함수를 사용하는 것이 좋은지 알아보기 위함이다. 결과는 아래의 그림과 같다.
4. Different stages
이 실험은 각 스테이지 별로 SE block을 넣었을 때, 성능에 어떠한 영향을 미치는지에 관한 것이다. 아래의 그림과 같이 어느 스테이지든 SE Block을 넣었을 때 성능이 개선됨을 알 수 있다. 그리고, 모든 스테이지에 SE block을 넣었을 때 성능이 가장 개선된 것으로 보아 각 스테이지의 SE block이 상호보완적임을 알 수 있다.
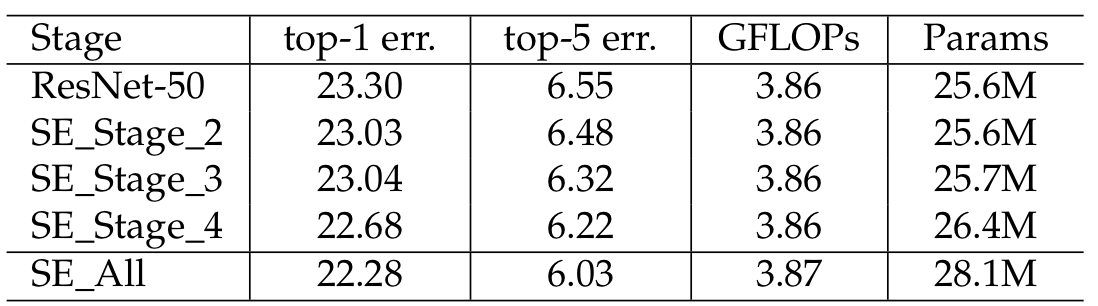
Role of SE blocks
1. Effect of Squeeze
이 실험은 Squeeze 연산의 중요성을 파악하기 위해 진행되었다. 이를 위해, 2개의 FC layer를 1 x 1 Conv로 교체하였고, 이를 No squeeze라하였다. 결과에서 보이다시피, Squeeze 연산이 있을 때 성능이 가장 좋았고, 저자는 이것이 global information 덕분이라 한다.
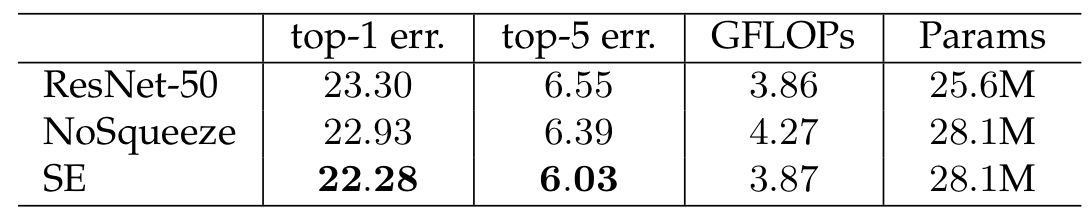
2. Excitation
Excitation 연산의 역할을 파악하기위해서 다른 클래스를 비교하였다. 클래스는 glodfish, pug, plane과 cliff를 사용하였다. validation dataset에서 클래스 별로 50개의 샘플들을 뽑고, 각각의 스테이지 별로 마지막 SE block에서 50개의 activation들을 평균냈다고 한다.
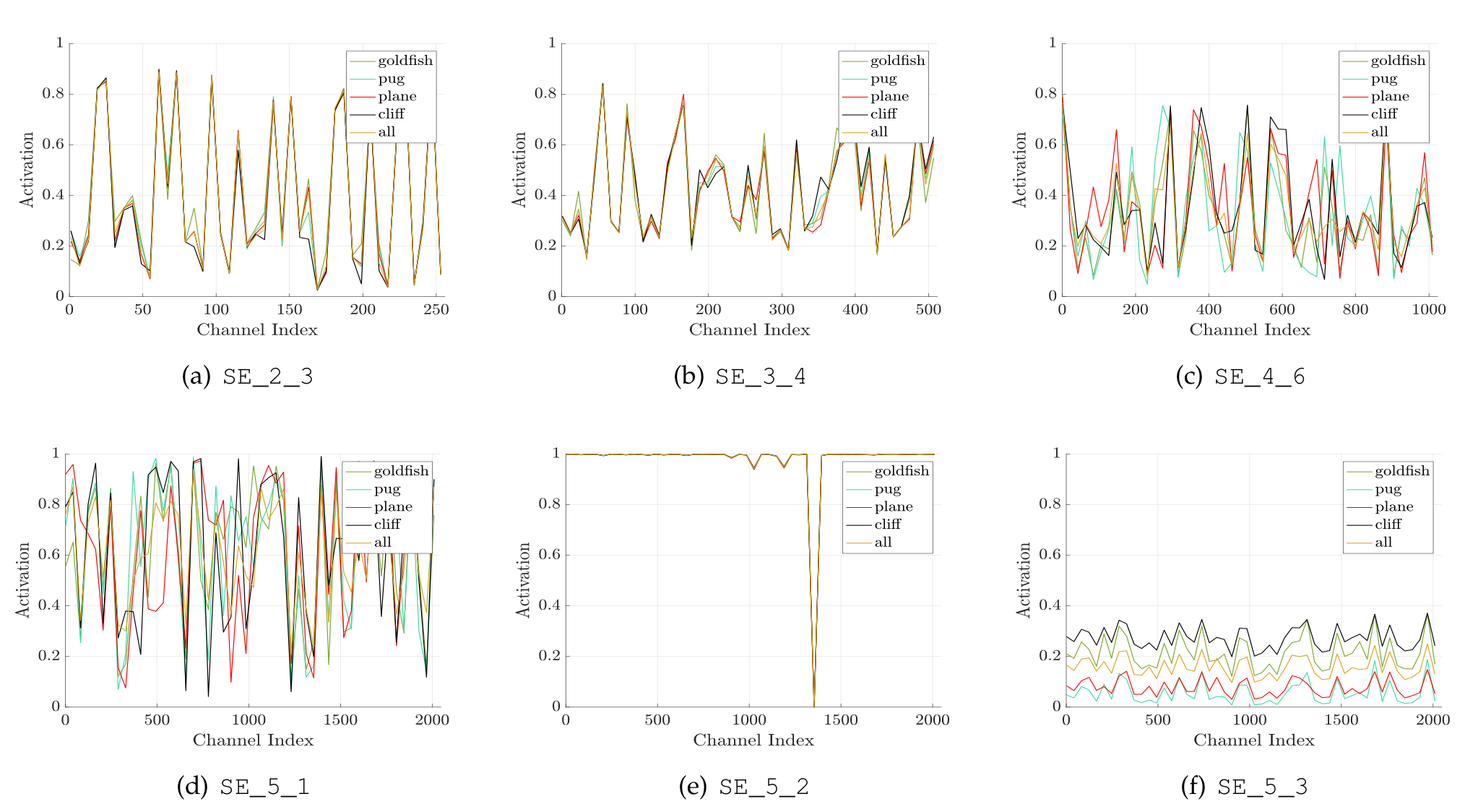
- 초기 excitation 연산에서는 클래스와 무관하게 유사한 activation을 갖는다. 이것은 feature channel의 중요도가 초기 스테이지에서는 다른 클래스와 공유됨을 의미한다.
- 후반부로 갈수록, 각각의 채널은 클래스에 의존하여 값들이 정해진다. 이를 통해, 초기 레이어에서는 일반적인 특징을 추출하고, 후반부 레이어에서는 클래스와 관련된 특징을 추출함을 알 수 있다.
- SE_5_2와 SE_5_3을 보면 값들이 거의 유사함을 알 수 있고, 이전 SE_4_6이나 SE_5_1보다 recalibration을 못함을 알 수 있다. 실제로, 마지막 스테이지의 SE block을 제거해도 성능은 크게 감소하지 않았다고 한다.
Discussion
SENet은 Squeeze 연산을 통해 global information을 추출하고, Excitation 연산에서 이를 조정하여 원래 채널에 곱해주는 SE block을 사용함으로써 성능을 개선시킨 모델이다. 또한, SE block은 다른 기존 모델에 끼워넣을 수 있어 구현도 쉽게 가능하다는 장점이 있다.
'Classification' 카테고리의 다른 글
| [논문 정리] NasNet (0) | 2022.12.14 |
|---|---|
| [논문 정리] CondenseNet (0) | 2022.12.12 |
| [논문 정리] ShuffleNet v1 (0) | 2022.12.10 |
| [논문 정리] PyramidNet (0) | 2022.12.04 |
| [논문 정리] PolyNet (0) | 2022.12.04 |



