
- deep learning
- SPP-Net
- overfeat
- object detection
- Weight initialization
- 딥러닝
- Convolution 종류
- Optimizer
- LeNet 구현
- image classification
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Today
- Total
I'm Lim
Kaiming He initialization 본문
Paper
He, Kaiming, et al. "Delving deep into rectifiers: Surpassing human-level performance on imagenet classification." Proceedings of the IEEE international conference on computer vision. 2015.
Kaiming He initialization
Xavier Initialization의 가정 중 하나는 activation function이 linear여야한다는 것이다. 이는 ReLU에서 성립되지 않는다. 따라서, Kaiming He는 이를 해결하기 위해서 ReLU activation function에 맞는 He iniitalization을 고안하였다.
Kaiming He initialization 증명



논문에서는 Forward case나 Backward case 중 하나만 사용해도 충분하다고 한다. 그 근거로 backward의 식을 forward에 대입하게 되면 $\dfrac {c_2}{d_L}$ ( 즉, 첫번째 conv layer의 채널의 수 / 마지막 레이어의 채널의 수 ) 가 남게 되는데, 이는 gradient vanishing / exploding을 발생시키는 요인이 아니기 때문이다.
Kaiming He initialization 공식
- Kaiming He Uniform Initialization
- $X \sim U(- \sqrt {\dfrac {6}{fan_{in}}}, \sqrt {\dfrac {6}{fan_{in}}})$
- Kaiming He Normal Initialization
- $X \sim N(0, \dfrac {2}{fan_{in}})$
Kaiming He initialization vs Xavier initialization
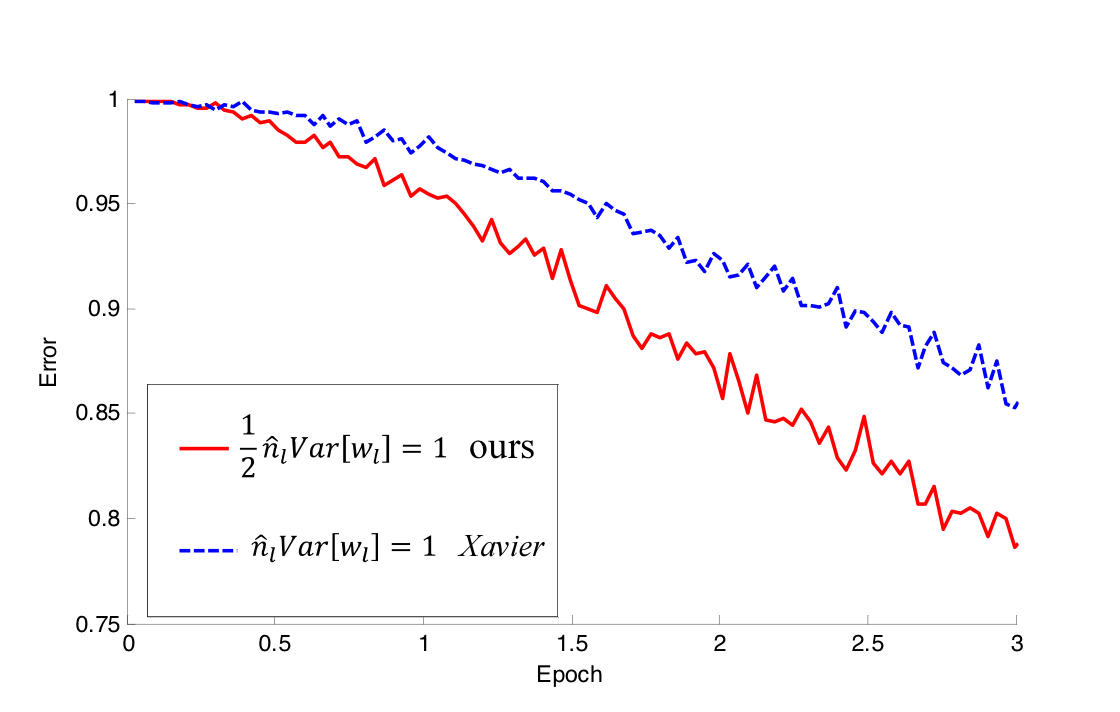
다음 그림은 ReLU activation function을 사용한 22 layer를 가진 모델에 Xavier initialization과 Kaiming He initialization을 비교한 것이다.
다음 그림은 ReLU activation function을 사용한 30 layer를 가진 모델에 Xavier initialization과 Kaiming He initialization을 비교한 것이다.
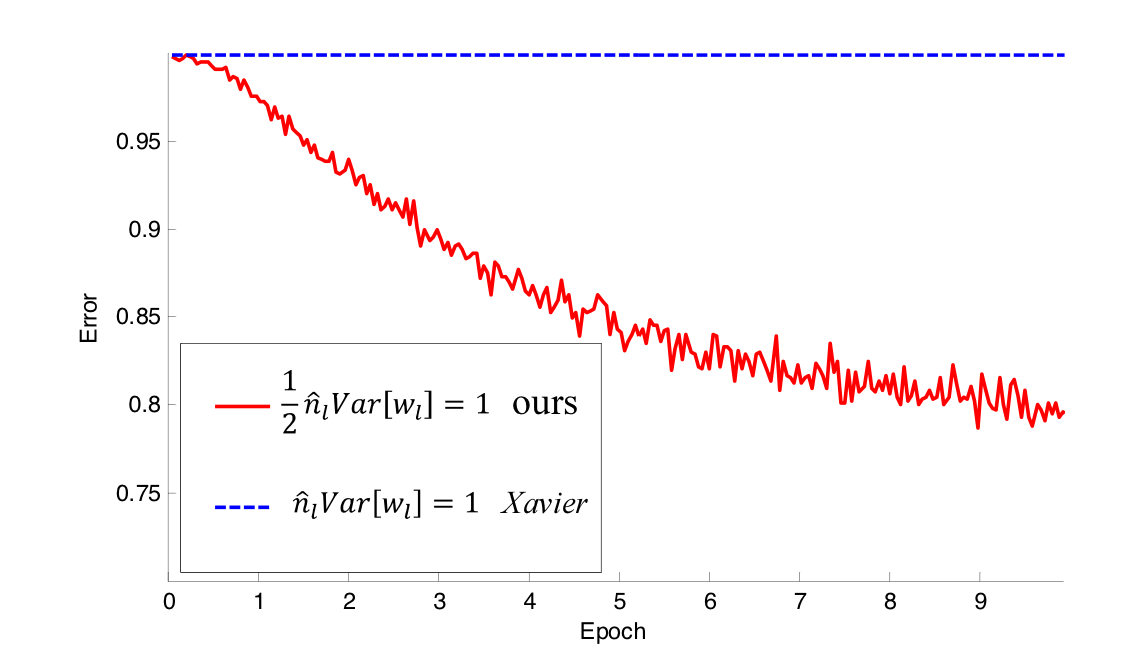
보이다시피, 레이어의 깊이가 얕은 모델 (그림 1)에서는 Xavier와 He initialization 모두 학습하는 것을 볼 수 있지만, He initialization이 더 빨리 학습하기 시작한다. 또한, 성능도 He initialization을 사용했을 때, 더욱 우수하였다고 한다.
다음으로, 레이어의 깊이가 깊은 모델 (그림 2)에서는 Xavier initialization을 사용했을 때, 학습을 전혀 하지 않았지만 He initialization을 사용했을 때는 학습을 잘 하였다. 이를 근거로 논문에서는 레이어를 깊이 쌓으려면 He initialization을 사용하는 것이 좋다고 말한다.
'Deep Learning > Weight Initialization' 카테고리의 다른 글
| Xavier Initialization (0) | 2022.10.23 |
|---|---|
| Lecun Initialization (0) | 2022.10.23 |
| Random Initialization (0) | 2022.10.23 |
| Zero Initialization (0) | 2022.10.23 |
| Weight Initialization (1) | 2022.09.30 |



