
- Weight initialization
- Convolution 종류
- Optimizer
- overfeat
- LeNet 구현
- image classification
- SPP-Net
- object detection
- 딥러닝
- deep learning
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Today
- Total
I'm Lim
[논문 정리] SPP-Net 본문
Paper
He, K., Zhang, X., Ren, S., & Sun, J. (2015). Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE transactions on pattern analysis and machine intelligence, 37(9), 1904-1916.
Abstract
기존의 CNN 모델 ( e.g, VGGNet, GoogLeNet, etc ) 등은 224 크기의 고정된 이미지 사이즈를 입력으로 사용합니다. 논문에서는 이것이 성능 저하를 야기할 수 있다고 주장합니다. 이를 해결하기 위해, Spatila Pyramid Pooling 개념을 도입하여 위와 같은 제한을 없앴습니다. 그 결과, Classification과 Object detection 분야에서 우수한 성능을 기록했다고 합니다.
SPP-Net은 Object Detection 학습을 위해 단 한장의 이미지만 입력으로 사용합니다. 그 결과, R-CNN과 거의 유사한 성능을 보임과 동시에 inference time이 24에서 102배 더 빨랐다고 합니다.
Spatial Pyramid Pooling
Overfeat에서도 말씀드렸다시피, Classification 모델이 고정된 이미지 크기를 입력으로 받는 이유는 Fully Connected Layer 때문입니다. SPP-Net은 마지막 Conv 레이어에 SPP Layer를 적용함으로써 이러한 제한을 제거하였다고 합니다.
SPP-Net은 고정된 이미지크기라는 제약이 없기 때문에 아래와 같이 Crop / Warp과정이 생략됩니다.

1. Spatial Pyramid Pooling의 장점
- 입력 이미지의 크기와 무관하게 spatial pyramid pooling layer의 출력의 길이는 동일합니다.
- spatial pyramid pooling은 여러 spatial bins를 가질 수 있습니다. ( 여러 max pooling을 동시에 적용가능 )
- 입력 이미지의 크기와 무관하므로 다양한 scale로부터 feature를 추출할 수 있습니다.

2. R-CNN과의 차이점
R-CNN은 Selective search로부터 추출한 proposal들을 전부 CNN의 입력으로 사용했습니다. 하지만, SPP-Net은 이러한 과정없이 원본 이미지를 입력으로 사용하여 단 한번의 CNN 연산을 거칩니다.
Training the Network
1. Single-size training
입력이미지를 224 x 224로 Crop하여 사용합니다.
2. Multi-size training
SPP-Net은 어떠한 크기의 이미지도 입력으로 사용할 수 있습니다. 그렇기 때문에, 180 x 180 과 224 x 224의 이미지 크기를 입력으로 사용하여 에폭마다 입력의 크기를 번갈아가면서 학습을 진행합니다.
SPP-Net for Image Classification
ImageNet 학습을 위한 Baseline 모델로는 ZF-5, AlexNet-5, Overfeat-5/7을 선택했습니다. ( 각 모델 이름 뒤 숫자는 conv layer 개수 ) 또한, 4-level pyramid를 택했는데 {6 x 6, 3 x 3, 2 x 2, 1 x 1}입니다.

결과는 위와 같이 SPP를 적용하고, Multi-size로 학습시킨 모델이 성능이 가장 우수함을 알 수 있습니다.
SPP-Net for Object Detection
R-CNN은 2000개의 proposal들을 selective search를 통해 추출하고, 227 크기로 resize한 이미지를 입력으로 사용합니다. 다시 말해, 이미지당 2000개의 이미지가 반복적으로 연산하여 많은 시간을 소요하게 됩니다.
SPP-Net은 전체 이미지를 단 한번만 사용해 feature를 추출합니다. 따라서, R-CNN보다 훨씬 더 짧은 시간을 소요합니다.
1. Detection Algorithm
Detection의 과정은 아래와 같습니다.
- 입력 이미지에 selective search를 적용해 2000개의 proposal들을 얻습니다.
- CNN모델의 입력으로 사용하여 feature map들을 추출합니다.
- 2000개의 proposal 좌표를 이용하여 feature map의 경계를 제한합니다.
- 경계가 제한된 feature map을 SPP Layer의 입력으로 사용합니다.
- SPM Layer의 출력을 FC Layer의 입력으로 사용합니다.
- R-CNN의 SVM과 동일한 방식으로 클래스를 분류합니다.
- (bb의 경우) R-CNN의 Box Regressor와 동일한 방식으로 bounding box를 예측합니다.
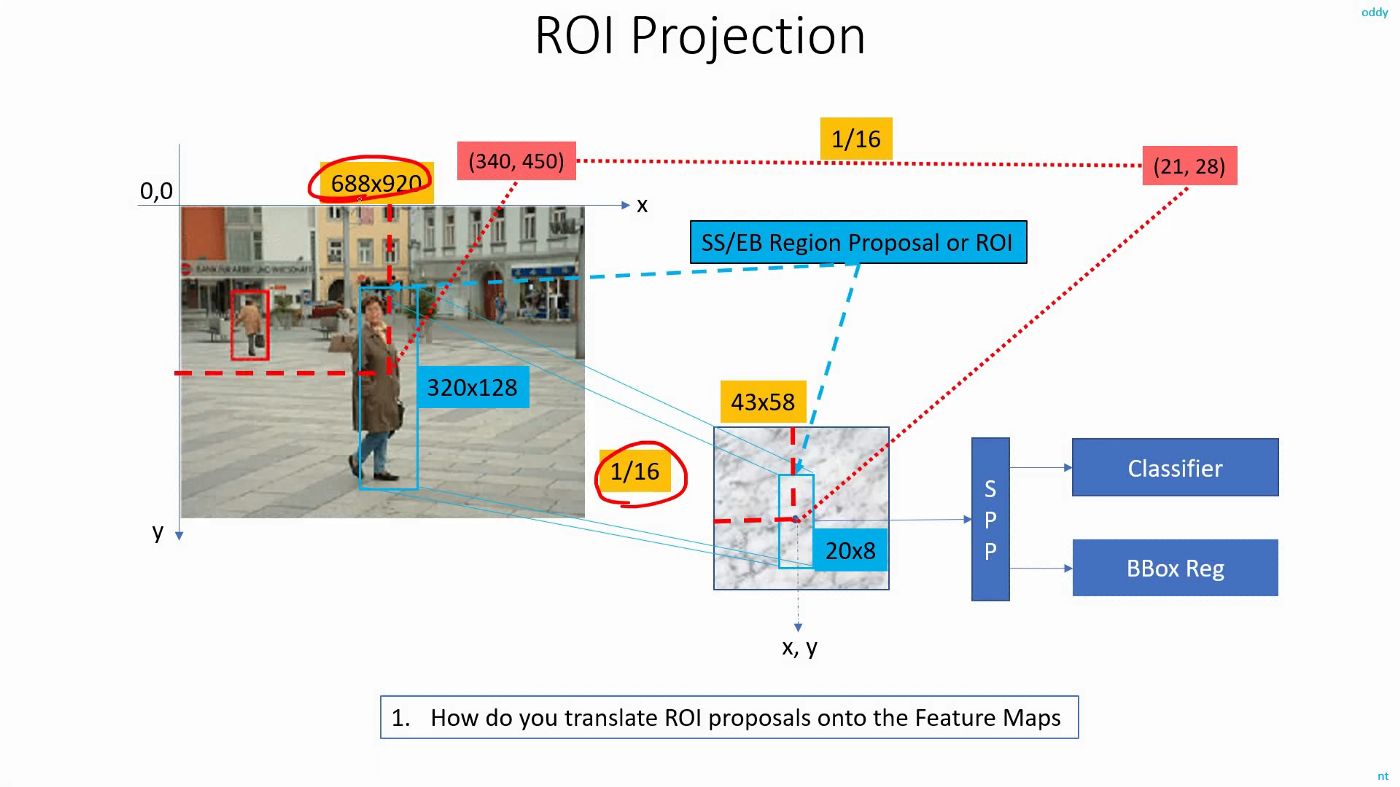
2. Detection Results
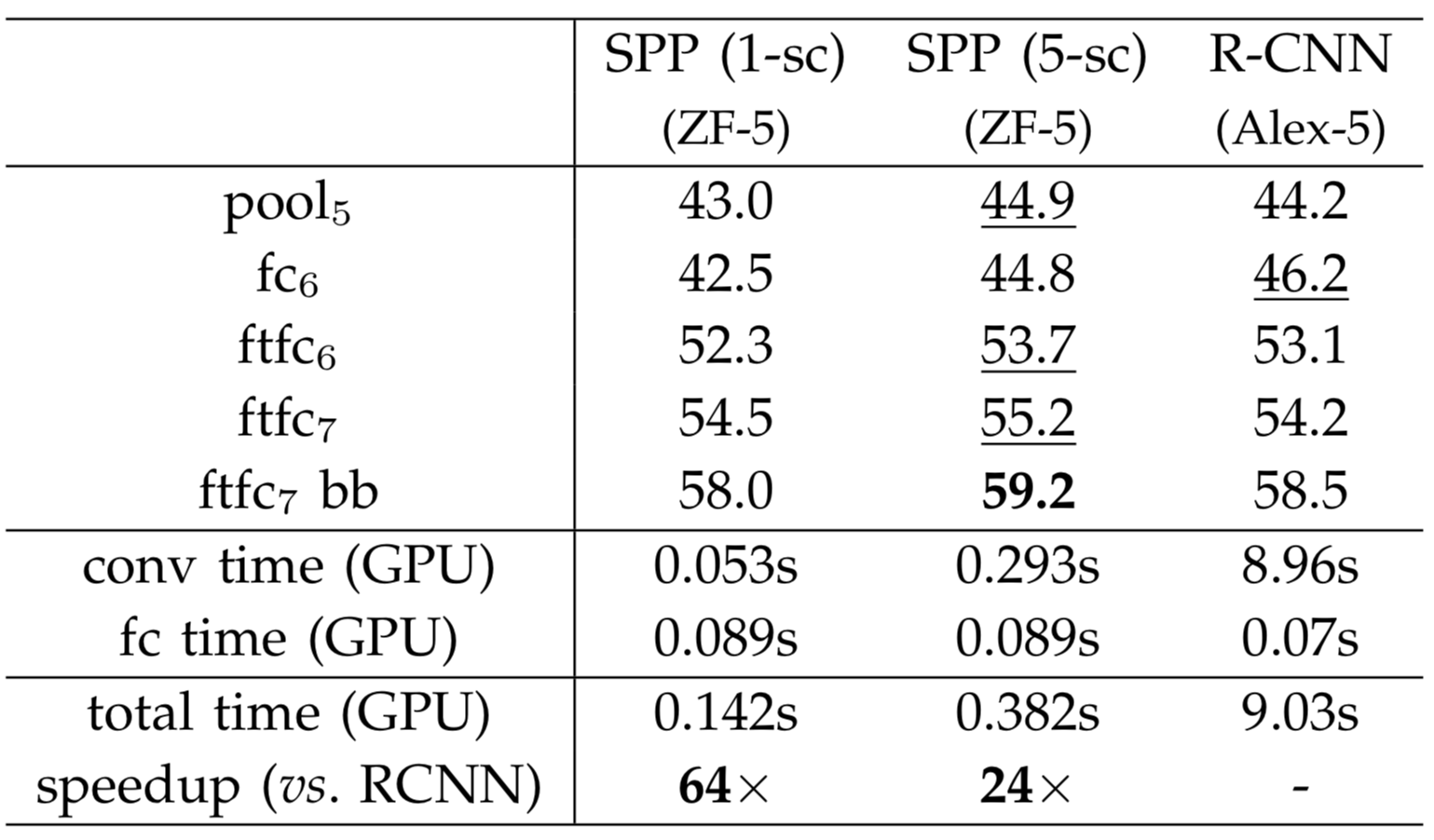
결과는 표에서도 알 수 있듯이 SPP-Net을 이용한 model이 R-CNN과 유사한 성능을 보이지만, inference time은 훨씬 빨랐음을 보여줍니다.
Appendix & Question
1. R-CNN과의 차이점
논문에서도 강조하다시피, R-CNN과의 가장 큰 차이점은 CNN 모델의 연산횟수다. R-CNN은 selective search로부터 얻은 proposal들을 전부 CNN 모델의 입력으로 사용하는 반면, SPP-Net은 원본 이미지 단 하나만을 CNN 모델의 입력으로 사용한다. 이후, 학습 방식 자체는 동일하다.
2. Overfeat과의 차이점
Overfeat은 region proposal을 통해 얻은 proposal들을 CNN 모델의 입력으로 사용하지 않는다는 점에서는 유사하지만 region proposal이 feature에 영향을 끼치진 않는다. 그에 반해, SPP-Net은 feature map의 경계를 region proposal을 통해 결정한 후, SPP Layer의 입력으로 사용된다.
'Object Detection' 카테고리의 다른 글
| [논문 정리] Fast R-CNN (0) | 2023.02.19 |
|---|---|
| [논문 정리] Overfeat (0) | 2023.02.05 |
| [개념 정리] Non Max Suppression (0) | 2023.01.24 |
| [논문 정리] R-CNN (0) | 2023.01.24 |
| [개념 정리] Object Detection Region Proposal (0) | 2022.12.27 |



