
- Convolution 종류
- image classification
- SPP-Net
- 딥러닝
- deep learning
- Weight initialization
- overfeat
- object detection
- Optimizer
- LeNet 구현
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Today
- Total
I'm Lim
[논문 정리] R-CNN 본문

Paper
Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 580-587).
Introduction
저자는 R-CNN 모델이 첫 번째로 ILSVRC 2012 우승 모델인 AlexNet을 사용하여 성능을 기존 모델 대비 30% 이상 올렸다는 점과 파인튜닝을 통해 성능을 향상했다는 점을 논문의 핵심 포인트로 꼽았습니다.
R-CNN은 이름 그대로 Region Proposal과 CNN 모델을 결합시킨 모델입니다. 논문에서는 R-CNN을 학습시키기 위해 PASCAL VOC 데이터 셋을 사용했습니다. PASCAL VOC는 train 데이터와 val 데이터를 합쳐도 12000개가량으로 CNN모델을 학습시키기에 부족했고, 저자는 이를 해결하기 위해 ImageNet 데이터셋으로 학습된 AlexNet에 파인튜닝을 하였다고 합니다.
Object detetcion with R-CNN
R-CNN 모델은 세가지의 프로세스로 구성됩니다.
1. Region proposal
R-CNN은 region propsal을 위해 Selective search 방식을 이용합니다. (Sliding window 방식도 고려는 했으나, CNN 모델의 Receptive field의 크기와 Stride가 커서 사용하지 않았다고 합니다)
2. Feature Extraction
AlexNet 모델에 Selective Search를 통해 얻은 proposal들을 전부 집어넣고, 일곱 번째 단의 출력인 4096차원의 feature vector를 추출합니다. CNN 모델은 고정된 이미지 크기를 입력으로 받기 때문에 이미지 크기를 Resize 시켜야 합니다. 저자는 이미지의 크기나 이미지 가로 세로 비율을 고려하지 않고, proposal 주변 16픽셀을 포함하여 Resize 시켰다고 합니다.
※ CNN이 고정된 이미지 크기를 입력으로 받는 것은 classifier 역할을 하는 fully connected layer 때문입니다. 이에 관련된 내용은 Overfeat 논문에서 나옵니다.
3. SVM
학습된 CNN 모델으로부터 얻은 feature vector들을 이용하여 클래스 별로 SVM을 학습합니다. SVM은 객체인지 아닌지 판별하는 역할을 합니다. ( 즉, PASCAL VOC는 클래스가 20개이므로 21개의 SVM을 요구합니다 )
요약하자면, R-CNN은 다음과 같은 과정을 거칩니다.

- Selective search를 통하여 proposal들을 추출
- 각 proposal을 학습된 AlexNet의 입력으로 사용하여 일곱 번째 단의 출력 ( feature ) 추출
- 클래스에 해당하는 feature를 이용하여 SVM 학습
CNN 모델 학습 ( Feature Extractor )
1. Supervised pre-training
위에서 나온 AlexNet 모델을 학습시키기 위해 우선 ImageNet 데이터를 이용하여 학습을 진행합니다. 이는 Image Classification 학습을 의미합니다.
※ R-CNN 모델은 그 목적이 Object Detection이므로 Classification이 목적인 ImageNet 데이터 셋에 학습된 AlexNet을 Auxiliary dataset에 학습되었다고 말합니다.
2. Domain-specific fine-tuning
Pre-trained된 AlexNet을 가져와서 마지막 단의 Linear Layer의 출력 클래스 개수만 데이터 셋에 맞게 바꾼 뒤, 모델을 파인튜닝시킵니다.
※ 이 때, Selective search를 통해 얻은 proposal들이 입력으로 사용되는데, 실제 객체의 위치 (바운딩 박스)와의 IOU가 0.5 이상이라면 positive, 그렇지 않으면 negative로 둡니다. ( Positive는 객체에 해당하는 클래스이고, Negative는 Background인 듯합니다 )
※ positive에서 32개의 샘플, negative에서 96개의 샘플을 가져와 미니배치 사용하여 학습을 진행합니다.
Test
Selective search의 fast mode를 이용하여 2000개의 proposal들을 추출하여 이를 CNN 모델의 입력으로 사용합니다. 그 이후, Non Max Supperession을 통해 겹치는 영역들을 제거한다고 합니다.
Pascal VOC 2010 Result

표에서 보이다시피, R-CNN이 기존의 모델들보다 우수함을 알 수 있습니다.
Bounding Box regression
예측된 바운딩 박스는 당연히 실제 바운딩 박스와 차이가 나기 때문에 이 오차를 줄이고자 AlexNet의 5번째 Conv Layer에 Pooling이 적용된 출력을 feature로 사용하여 ridge regression을 진행하였다고 합니다. 선형 회귀를 위해, 아래의 식을 사용합니다.

$\hat{G}$ 는 예측 바운딩 박스입니다. 즉, 우리가 찾고 싶은 것은 $\hat{G}$ = $G$가 되도록 하는 $d(P)$입니다. 이를 만족하는 $d(P)$를 $t$라고 하면 아래와 같이 나타낼 수 있습니다.

$d(P)$를 $t$ 에 근사화시키는 릿지 회귀를 식으로 나타내면 아래와 같고, 이것이 bounding box regression입니다.
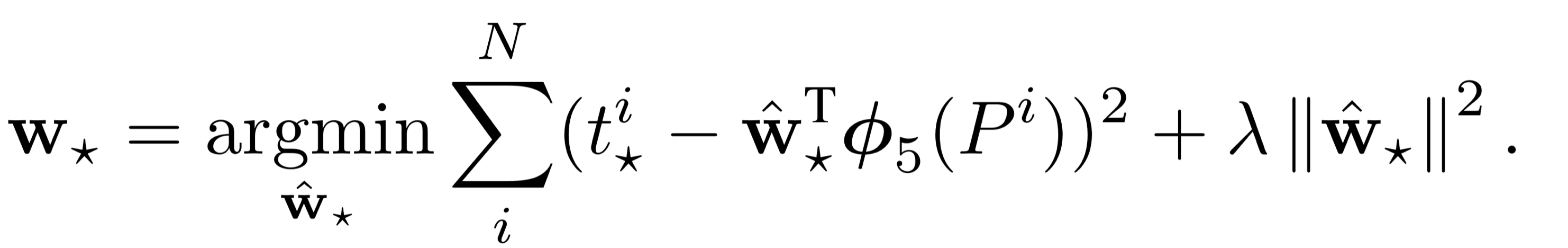

Reference
Appendix & Question
1. SVM vs Softmax Layer
: 처음 논문을 읽을 때는 Domain-Specific fine-tuning과정에서 이미 분류를 위한 학습을 진행하였는데 왜 SVM을 사용하는지가 이해가 되지 않았다. 해답은 Appendix에 나와있었는데 SVM을 사용한 이유는 성능이 더 잘 나와서라고 한다.
: Domain-specific fine-tuning과정으로 객체 분류 학습을 진행하고, 다시 한번 SVM을 통해 객체 분류 학습을 시킨게 맞다.
2 ) Bounding Box
: Result 표에서 R-CNN과 R-CNN BB가 분리된 것을 보고, R-CNN는 bounding box를 어떻게 예측하는지에 대한 의문이 생겼다.
: 해답은 표에서 나온 R-CNN은 bounding box regression을 진행하지 않는다. 그 이유는 Selective search를 통해 얻은 proposal 자체가 bounding box이기 때문이다. ( 파이썬을 이용하여 Selecitive search를 이미지에 적용하면 bounding box 좌표를 반환한다 )
: R-CNN은 selective search를 통해 추출한 고정된 bounding box의 객체여부를 다루는 문제로 볼 수 있다 ( SVM ). 여기서 한발 더 나아가, R-CNN BB는 selective search를 통해 얻은 bounding box의 좌표를 실제 bounding box에 근사화하는 작업 ( Ridge regression )까지 진행한다고 볼 수 있다.
'Object Detection' 카테고리의 다른 글
| [논문 정리] Overfeat (0) | 2023.02.05 |
|---|---|
| [개념 정리] Non Max Suppression (0) | 2023.01.24 |
| [개념 정리] Object Detection Region Proposal (0) | 2022.12.27 |
| [개념 정리] Object Detection Metric (0) | 2022.12.25 |
| [데이터 셋] COCO dataset (1) | 2022.12.24 |



